It seems the multitude of equivocal trials in heart failure with preserved ejection fraction (HFpEF, “diastolic heart failure”) fit into this same story. A heterogenous syndrome with multiple, often disparate, pathophysiologic endotypes that unsurprisingly won’t always have consistent response to a given intervention.
3 Likes
Yes Dr. Andrew.
I was a little older than you when I was studying time series data of “Sleep Apnea Syndrome” from the sleep lab at Ohio State and discovered the Apnea Hypopnea Index (AHI) was simply a guessed measurement with minimal capture of the actual time series of perturbations and recoveries. In addition to being guessed (without data) anyone with a moderate understanding of time series related pathophysiologic perturbation could see that AHI was not a valid measurement. I thought this was a revelation. The stunning thing to me was that no one cared.
You see, thought leaders of the day would see a dysfunction, define mathematical measurements of the dysfunction, call the dysfunction a “Syndrome”, and then acquire grants to study the population with “The Syndrome” using RCTs as if the syndrome was a disease. Of course this actually captured a SET of diseases. The NIH accepted the “syndrome” as real and forced those studying the diseases in the SET to use the syndrome measurements (which, of course were nothing more than threshold or threshold set of measurements of a common dysfunction or set of dysfunctions.)
There is a move to recognize the presence of “phenotypes” or “sub phenotypes” of a syndrome (and I have been guilty of using that euphemistic terminology) but this approach fails to address the fundamental error. Again, the fundamental error is that a standard measurement defines a dysfunction induced by a SET of diseases. It does not define a single disease or “syndrome” with phenotypes.
The phenotype concept is certainly not a valid compromise of the thought leaders of Syndrome Science if the original threshold measurements (such as the AHI, SIRS, SOFA , AKI, or Berlin) are still used to define the SET. Indeed each disease in the SET has its own phenotypes. This nascent “phenotype” approach to the SET seems like progress but the SET is still defined by the old measurements. This compromise, which is an extension of the pathologic science, could take another generation to extinguish.
Only full wide recognition by scientists of your generation and the promulgation and broad acknowledgement of this simple apical 20th century cognitive error which initiated this pathological “Syndrome Science” will solve this problem. Its best to start with the math and show why an RCT applied to a measurement which captures a population of a fluidic SET of diseases is not based on a valid function. I can assure you that (as Dr. Kuhn has taught) even decades of compelling arguments or words (like the ones I have made here) will not work to change the older minds of those holding these dogma.
If you did not read this article it is worth review because shows the profound consequences and depth of institutional anchor bias in “Syndrome Science”. It really does not matter if one believes that the old ARDS protocol failed or not, the lesson is clear. Syndrome Science is pathological science.
I call this “Boomer Science” because scientists of the heady baby boomer generation (like me) believed and taught these measurements as they were as valid as the definition of torque. I look back and its hard to believe how naïve and trusting I was especially given that I had been taught by an undergraduate mentor that a good scientist questions all dogma.
I hope you will send this link to others in your group to get the discussion going. Only a youthful “revolution of understanding” of this pathologic science will bring timely change.
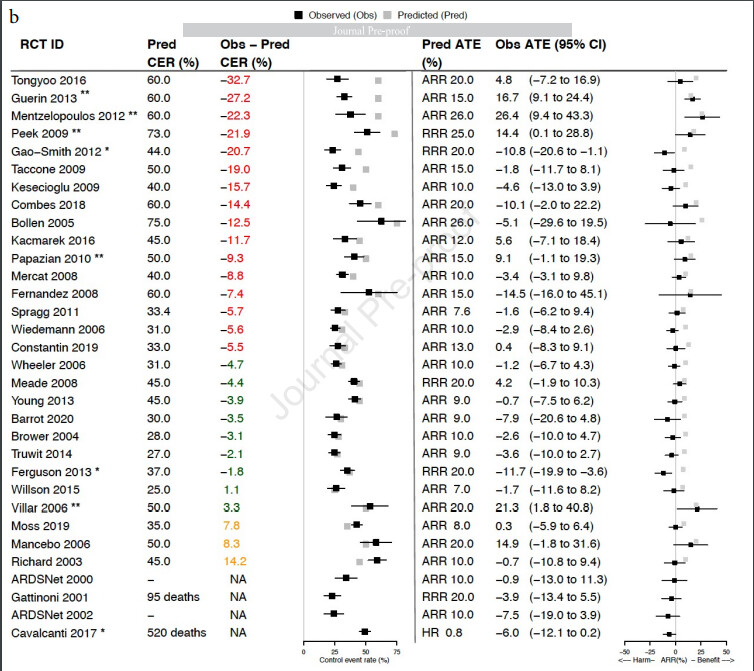
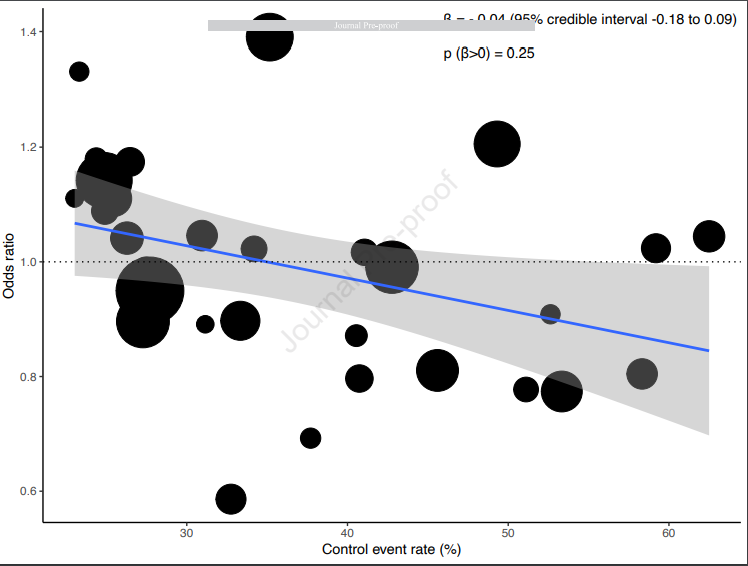
Stunningly relevant article examining RCT using 20th century “Syndrome Science”. Note the review includes Acute Respiratory Distress Syndrome (ARDS) trials after the 1994 consensus definition of ARDS and before COVID (2020)…
https://journal.chestnet.org/article/S0012-3692(22)01045-5/pdf
Note the examination of the average treatment effect (ATE) and the predicted Control-arm Event Rate (CER)
Here you see the characteristics of perceived introspection but entirely within the Syndrome Science Dogma.
The authors recognize there is a profound problem with the methodology but fail to see that the syndrome criteria define a fluidic SET of diseases so that each RCT is applied to a different SET of diseases which they think is an actual unifying disease (syndrome) defined by the consensus criteria.
In other words, they are fooled by the all embracing syndrome terminology of the past, conflating a SET of diseases with a single contrived “all cause” entity captured by the 20th century threshold criteria (as amended). The “All-Cause ARDS” studied here exists only in their minds.
I hope that we will have some input here discussing the results.
1 Like
Lawrence:
The concerns you raise are compelling, but I’m not sure how feasible it would be for a statistician to produce/“model” an empiric demonstration of your argument. If I’m not mistaken, it sounds like you’re asking for someone to write a paper that models the consequences of extreme patient/treatment interaction on outcomes of an RCT, with the interaction being driven by inclusion of subjects who should never have been “lumped” together in the first place.
You might be interested in this recent publication. It addresses a lot of the issues you raise:
“Diagnoses do not carve nature at her joints, but are pragmatic kinds: things constructed (in part based on evidence) to be useful for specific purposes (Kendler et al., 2011). Elements listed in psychiatry’s DSM are different than elements listed in chemistry’s DSM, the periodic table. Helium and magnesium are natural kinds: unchanging entities with necessary and sufficient properties that clearly define them. Every atom with 2 protons is helium, and helium’s internal structure defines kind membership, not expert consensus. Unlike MDD and schizophrenia, there is only one definition of helium; helium can be diagnosed with perfect reliability; and it can be clearly distinguished from magnesium.”
…”While reductionism has been astonishingly successful in science, its limits became clear in the 20th century when trying to understand increasingly complex systems, such as the stock market, the weather, the internet (Barabási, 2012), or—as I argue here—mental disorders. This is because complex systems contain inter-dependent elements whose properties depend on each other, calling for the study of parts and their relationships.”
In (probably embarrassingly) crude terms, it seems that if we’re going to apply RCT methods with a reasonable expectation of identifying the intrinsic efficacy of any proposed treatment for a condition of interest, we need:
-
At least one “essential” patient-level characteristic that is invariably present in patients with the condition under study AND that can be reliably (and ideally objectively) measured/identified AND that has a strong and well-characterized relationship with the clinical outcome(s) of interest. This feature should be used as an inclusion criterion for the trial. If such a feature is absent, there is a good chance that signals of treatment efficacy will be obscured by “noise.” Unless we’re confident that subjects whom we’re including in a trial are sufficiently similar with regard to the essential nature of the underlying condition being treated, there will be potential for extreme heterogeneity in treatment response. This criterion would not be fulfilled by conditions diagnosed on the basis of sign/symptom “menus” (e.g., “to meet the diagnostic definition, the patient must meet >X of the following criteria,” or “patient must meet at least X “major” and Y “minor” criteria”).
-
To understand the natural history of the condition we are treating well enough that we can identify potential trial subjects who are at similar points in their clinical trajectory when they are exposed to the experimental treatment. It might not be reasonable to expect a treatment’s efficacy to manifest when it is applied at different points in a patient’s clinical trajectory (?) Treating a group of patients who are at wildly different points in their clinical trajectory could further amplify any “noise” in the results. It can be harder to meet this criterion when studying conditions with significant potential for spontaneous fluctuation in symptom severity- these conditions tend to be harder to study.
The above criteria don’t apply to preventive therapies like vaccines.
Examples of conditions that seem to meet criteria 1) and 2):
- Heart failure with reduced ejection fraction (established efficacious treatments: ACE/ARB; beta blockers; MRAs; SGLT2 inhibitors)
- Acute occlusion MI (primary PCI, thrombolytics)
- Bacterial meningitis (antibiotics)
- Atherosclerotic coronary artery disease (statins, ASA)
- Acute large vessel ischemic stroke (thrombectomy)
- Treatments for smoking or alcohol cessation (varenicline, wellbutrin, naltrexone)
Examples of conditions that might not meet criteria 1) and 2):
- Depression
- Chronic pain
- Sepsis
- Sleep apnea
- ARDS
- Heart failure “with preserved ejection fraction”
- “Unstable angina” (?)
- Irritable bowel syndrome
- Polycystic ovarian syndrome
- People with very brief runs of atrial fibrillation detected incidentally on wearable devices (?risk/benefit for anticoagulation in patients with very low a.fib burden)
- “Mild cognitive impairment”
It would be interesting to construct a more complete inventory of medical conditions that are harder to study because of “fuzziness” in how they are defined. I bet the list would be very long…
5 Likes
This reference is excellent. The fundamental problem with “Syndrome Science” is diagnostic literalism
I believe this will be a challenge but there is a urgent need for a solution as the diseases trapped within this paradigm are among those which are the greatest threats to the health and life of every human on the planet. In fact many of these diseases are so deadly that this precipitated the desire to move quickly to bring RCT to bear in the 1980s. Responsive to the urgent need, thought leaders of the 1980s bypassed the normal process of intensive study of the natural history of the diseases, and the factors which separated them and instead combined them into syndromes for immediate RCT.
So I will present the components of the model I am proposing but first considering the problem as you have described it.
I agree with your first point that an essential component is a reproducible objective measurement of these syndromes. Of course this is not possible in “syndrome science” because, using this methodology, a syndrome comprises a SET of different diseases and the percentage of each of the diseases in the SET in each new population under test will vary with each new RCT.
Instead, the 1980s guessed threshold criteria (as periodically amended) are used as the surrogate measurement for RCT applied to a “syndrome”. These capture a set of different diseases and are not real measurements of any “syndrome” or specific pathophysiologic condition so the RCT are not reproducible.
Your second point is absolutely correct.
This is exactly the study which was bypassed in the 1980s when scientists urgently moved directly to naming the syndromes and performing RCT. This was the essential step needed to determine (not guess) the objective measurements and to relate those measurements to the severity and trajectory of the disease. This bypassed step was required for the reproducible application of an RCT to investigate the treatment of a disease. This was the pivotal mistake which produced 30yrs of a Langmuir pathological science.
So, given the loss of life, physicians that now understand this pivotal mistake have an ethical obligation to seek to either expose the mistake or solve the problem, or both.
,
The first step is to convince thought leaders that 1980s “Syndrome Science” is pathological science . Given present knowledge of the behavior of scientific groups and paradigm leaders, this is the greatest hurtle. It cannot be overcome with words or teachings.
Only a compelling mathematical model will be successful. These are different diseases in the SET . These are NOT “sub phenotypes” of the same disease or “syndrome” as defined by the criteria. In fact each of these diseases has its own sub phenotypes. The guessed criteria does not capture a “syndrome”. That is only a cognitive entity existing in the mind, useful for clinically categorization, billing, and awareness but not for RCT. .
Here are the components of the proposed model.
With “Syndrome Science” each of these “syndromes” (eg sleep apnea ARDS, sepsis) is defined by threshold criteria which, instead of capturing a pathophysiologic entity, thing, or condition, captures its own SET of different diseases. This is accomplished using the 1980s types of guessed thresholds of nonspecific lab or vitals values as the capturing criteria as periodically amended.
The criteria for Sepsis for example captures toxic shock due to group A streptococcus, Candidemia due to a colonized catheter, mixed aerobic and anaerobic peritonitis due to perforated bowel, and pneumococcal bacteremia due to pneumonia. These are not “sub-phenotypes:” of the same syndrome these are different diseases combined into SET for RCT.. Sepsis therefore comprises a SET of different diseases arbitrability combined into a cognitive construct for RCT. The treatment may have a different average treatment effect for each disease and the percent mix of said SET will change with each RCT rendering repeat RCT nonreproducible.
The same it true for ARDS. The criteria for ARDS, for example, captures pulmonary dysfunction due to; post trauma or shock, bacteremia, influenza, pancreatitis, and SARS-COV2 (COVID). As with sepsis
these are not “sub-phenotypes” of the same syndrome (ARDS). They are a SET of different diseases arbitrability combined and given a name (ARDS) for study as a single entity using RCT.
Consider such a SET for study under RCT comprised of 5 diseases. (ARDS has at least 10 primary diseases, Sepsis at least 30, sleep apnea at least 6) .
Now consider treatment X with an average treatment effect on disease 1 of 20.5, disease 2 of 4.3, disease 3 of -5.6, disease 4 of 0.3, and disease 5 of -15.2.
Now consider 5 RCT studying the same treatment to for example “Sepsis” as specified by the threshold criteria, a first RCT which shows a statistically significant ATE for the SET of diseases and then 4 more repeat RCT applied using the criteria wherein the percentage of each disease within the SET is different for each new RCT.
This simulation would serve to show that RCT of a 1980s “syndrome”, which is actually comprised of a SET of different diseases, is nonreproducible and I believe the promulgation of that math is the required to overcome the institutional anchor bias and catalyze the introspection required. .
Given the stagnated state of this critical science relating to the public health, the public desperately needs the benefit of input, critique, comments and guidance from the many mathematicians in this group. As physicians, scientist and/or statisticians with the rare knowledge of the fundamental problem at this critical time, this is our responsibility and there is no timely back-up coming.
1 Like
Stunning how similar the instant problem with “Syndrome Science” in critical care is to the problems associated with the study of mental health conditions.
3 Likes
I have previously identified sleep apnea syndrome science as the most mature “Syndrome Science” for those wishing to study the social aspects of the evolution of syndrome science and the associated indoctrination and reviewer driven shepherding. This is a field in which my team performed extensive time series data research in the late 1990s and over many decades I watched (and tried to intervene) as the young were indoctrinated. It was very sad.
Here is how the lay public perceived the failure of the science "Sleep apnea specialists dumbfounded at critique of ‘gold standard’ treatment."
"Investigators noted that the studies used “highly inconsistent” definitions of breathing measures, respiratory events, and response to treatment, measured using the Apnea-Hypopnea Index (AHI) – a metric that the report also critiqued.
"No standard definition of this measure exists and whether AHI (and associated measures) are valid surrogate measures of clinical outcomes is unknown," the report states.
Elise Berliner, PhD, of AHRQ, told MedPage Today that addressing the inconsistencies and limitations of the existing studies should be a top priority of the sleep research community".
Of course I agree. I’ve been saying this for about 25yrs. They have heard me (My admonitions were really was hard to miss) and they ran away. Yet they are 25 yrs later …“Dumbfounded”?
You see, it may take decades but when pathological science fails it can do so in a catastrophic way. I’m sure most thought leaders were silent about the fact that the AHI was guessed and nonreproducible and did not tell the statisticians, who, were not aware that the gold standard metric was guessed by two guys in 1976 or that the AHI had proven nonreproducible, or that the syndrome included many diseases. I doubt anyone would have thought to ask but hopefully statisticians have learned the lesson of sleep apnea science because 20th century pathological syndrome science is alive and well in Sepsis, ARDS, and probably other fields of science.
Only you can do something about it and silence of the thought leaders in the face of challenge is the action which makes the youth think that I am wrong because certainly, they think, the leaders would confront this fool. No the opposite is true, with few brief exceptions, they have always been silent exactly because they know I am right and they don’t want to engage in a public debate where their weak dogma would be exposed. I watched the behavior for about 25 yrs. So predictable now. Very sad.
On the positive side, the solution is really a simple lesson Have the courage and due diligence to always confirm the integrity of “MDM”;
the Measurement,
the Data, and
the Math…
Now that sound trite, but the very dominance of syndrome science for over 3 decades shows its not trite, its Lynchpin thinking.
One final point:
Other than likes and encouragements (which I appreciate), I am the only one standing for general reform of syndrome science… Not one academic will engage in debate on twitter or here. I tried to get them here, no takers. I asked to speak at ACCP annual meeting, declined. I know I have an advantage, there is little risk for me as I don’t need their grants or promotions or covet their conference dinner invites but to those those of you who do, I say, sometimes you have to take a risk in the interest of science. Its 30+ yrs of failure, Its unequivocal. Don’t be silent, if for no other reason, help promulgate the need for reform for the youth. They are still being indoctrinated. .
You don’t have to believe me to forward this link or encourage a thought leader to comment here. However 25 yr history has proven that they are afraid and will not come. I need help. I cannot do this alone. Silence and lack of knowledge of this issue is an effective defense for the entrenched and empowered. Only promulgation, visibility, and open public debate can counter the silent keepers of the old ways.
1 Like
Well, just when I asked for help it arrives and unlike me, these are experts with political game, with political chops. .Many were on the other side advocating syndrome science for decades but that does not matter, they are now accelerating the shift. Thomas Kuhn says that when the experts move they move together. No expert wants to be the last one holding the old failed dogma.
This excellent article looks back at the failed history of Syndrome Science and provides a proposed platform for going forward. Unlike previous articles which flirted with the need for phenotyping but did not recognize that the syndrome science must be abandoned this article presents the truth boldly.
Quotes from the article:
"Research and practice in critical care medicine have long been defined by syndromes, which, despite being clinically recognizable entities, are, in fact, loose amalgams of heterogeneous states that may respond differently to therapy. Mounting translational evidence—supported by research on respiratory failure due to severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) infection—suggests that the current syndrome-based framework of critical illness should be reconsidered."
"*## Critical illness syndromes
*Most of the illnesses treated in the ICU are clinical syndromes. Conditions like sepsis, ARDS, acute kidney injury, delirium and even chronic critical illness are characterized not by any particular biopsy feature, genetic mutation, microbial culture or serologic test but, rather, by collections of signs and symptoms that together paint the picture of a clinically recognizable entity. As a result, critical illness syndromes are heterogeneous by nature. For instance, sepsis can arise from a multitude of infections, caused by many different pathogens and resulting in different patterns of organ injury. ARDS may arise from either pulmonary triggers (such as pneumonia or aspiration) or non-pulmonary triggers (such as trauma or pancreatitis), and delirium may manifest as both agitation and somnolence. There is also temporal heterogeneity; a patient meeting diagnostic criteria for one syndrome at a given time may progress through different, often disparate, phases. Added to this is the tremendous heterogeneity in the host response to injury from one individual to the next.""
The recognition that a standard syndrome science measurement for RCT (guessed criteria) actually captures SET of diseases rather than "phenotypes of the syndrome’ is a major step forward.
https://www.nature.com/articles/s41591-022-01843-x
What a great day this is. It was about 25 years ago when I discovered (reviewing our study at The Ohio State University) the first fake measurement (the AHI) defining a “syndrome” . I have been on this quest ever since. Earlier I would rise to the microphone at conferences to raise the issue, the speakers would quickly move on. I sought grants to show the truth (denied). I asked to speak at the ACCP (denied). I joined Twitter in 2012 for the sole purpose of bringing #SyndromeScience down (I called it #ThresholdScience back then).
I thought I had them convinced by showing their gold standard measurement for RCT (SIRS) was just a guess. However, .they came back in 2016 and brought out another 1990s guess SOFA as sepsis 3. At that time, it was clear they had not listened and they did not understand Syndrome Science was pathological science. They seemed so entranced that it could take 20 more years. I have to admit to a little time after they brought the SOFA score out of mothballs for sepsis 3 that I wondered if I could ever bring syndrome science down…
However, I knew Syndrome Science could not stand so I upped my twitter campaign and Joined @f2harrell s Datamethods Discourse and campaigned here. We then wrote a review to show how COVID cut Syndrome Science into shreds. I was determined to accelerate the collapse.
I’ve been called quixotic, and perceived as discontent, blocked, many followers abandoned me, but for a decade the thought leaders on social media and at the annual conferences ran away. However, once I understood how these fake measurements were generated and perpetuated, the other fake measurements of other “syndromes” were obvious. I also had much help and encouragement and I say thank you because you know who you are. I will not call out those forward looking experts because the political climate is still dicey.
Now it should be clear Syndrome Science was a broad 30+ year Langmuir pathological science. Everyone can see the truth…
There is no one to blame, everybody was trapped in the dogma. The field will soon be free from the shackles of 20th century thinking, I am finally excited for the future of critical care. This is a good day for critical care science.
3 Likes
Don’t miss discussion of “Pathological Consensus” on July 14th

1 Like
I’ve been contemplating the next step.
The thought leaders now see the past pathologic consensus methodology has failed but I don’t think they know why. They seem to think is garden variety (but very severe) heterogeneity. They are going to abandon the methodology but it wont be done quickly. Many will not get the word. It could take 3-5 years
I think what we need is a “RCT Methodology Recall”. Analogous to an automobile recall a RCT methodology recall is promulgated widely. This failed #PathologicalScience methodology was widely promulgated and mandated so the recall has to be widely promulgated lest many continue to do the failed research (drive the unsafe car), .
It’s the 21st century.
Let us call for the first RCT methodology recall in the history of woman
.
What do you think? .
“The primary thing that stands between knowing the right thing and doing the right thing, is fear.”
2 Likes
video provides about 19 min talk about RCT methodology and an 30 year era of failure in crit care RCT. The great new is that this can be fixed promptly.
We have a great opportunity for change. I hope many will spend the time to listen and help. Please provide feed back either here or in DM. Lets get this done…
3 Likes
I’ve watch the first part and based on that can very much recommend the video.
1 Like
Thank you for posting the video. I think that the issue of selecting subjects for RCTs also has implications for how diagnostic criteria are currently selected by consensus and the resulting problem of over-diagnosis. What are your thoughts about how diagnostic and RCT entry criteria should be established in a systematic and ‘evidence-based’ way?
1 Like
Thank you again for posting the video. I completely agree with you that arriving at diagnostic and treatment criteria in a non-evidence based consensus manner has caused all sorts of problems. This also means that the foundations of EBM are undermined. Another of the unfortunate consequences is over-diagnosis and over-treatment. The following abstract is based on a talk I gave at a workshop in Oxford in 2017 entitled ‘The scope and conventions of evidence-based medicine need to be widened to deal with “too much medicine” [1].
Abstract: In order that evidence‐based medicine can prevent “too much medicine”, it has to provide evidence in support of “gold standard” findings for use as diagnostic criteria, on which the assessment of other diagnostic tests and the outcomes of randomized controlled trials depend. When the results of such gold standard tests are numerical, cut‐off points have to be positioned, also based on evidence, to identify those in whom offering a treatment can be justified. Such a diagnosis depends on eliminating conditions that mimic the one to be treated. The distributions of the candidate gold standard test results in those with and without the required outcome of treatment are then used with Bayes rule to create curves that show the probabilities of the outcome with and without treatment. It is these curves that are used to identify a cut‐off point for offering a treatment to a patient and also to inform the patient’s decision to accept or reject the suggested treatment. This decision is arrived at by balancing the probabilities of beneficial outcomes against the probabilities of harmful outcomes and other costs. The approach is illustrated with data from a randomized controlled trial on treating diabetic albuminuria with an angiotensin receptor blocker to prevent the development of the surrogate end‐point of “biochemical nephropathy”. The same approach can be applied to non-surrogate outcomes such as death, disability, quality of life, relief of symptoms, and their prevention. Those with treatment‐justifying diagnoses such as “diabetic albuminuria” usually form part of a broader group such as “type 2 diabetes mellitus”. Any of these can be made the subject of evidence‐based differential diagnostic strategies.
In the Oxford Handbook of Clinical Diagnosis, I also suggest a way forward for medical students, medical scientists and doctors interested in a research career who need to work closely with statisticians. The maths has been improved and updated from that in the above paper in the final chapter of the 4th edition (that I am finalising at present) some of which having been described in my recent posts here on DataMethods [see links 2, 3 and 4 below]. I would be grateful for your views about how this corresponds with your vision.
Reference
1. Llewelyn H. The scope and conventions of evidence-based medicine need to be widened to deal with “too much medicine”. J Eval Clin Pract 2018; 24:1026-32. doi:10.1111/jep.12981 pmid:29998473. [The scope and conventions of evidence‐based medicine need to be widened to deal with “too much medicine” | Semantic Scholar]
2. Should one derive risk difference from the odds ratio? - #340 by HuwLlewelyn
3. The Higgs Boson and the relationship between P values and the probability of replication
4. The role of conditional dependence (and independence) in differential diagnosis
1 Like
This is very well said and presents another problem with “Pathological Consensus”, the amplification of disease and therefore amplification of the treated population “too much medicine” and therefore amplification of expense and unnecessary side effects. The recognition of the excess expense should be motivation alone for reforming the process of deriving consensus definitions.
That’s a great question and to answer it let us first look at sleep apnea. Sleep apnea also called the sleep apnea hypopnea syndrome (SAHS) comprises at least 6 different types of arrhythmia of breathing. Yet all are diagnosed and quantified by a simple sum of the apneas and hypopnea (10 second complete or partial breath holds). This 10 second rule was guessed for apnea in 1975 and hypopneas were added in the 1980s.
The original cutoff for the diagnosis was 30/per night and this was later changed to 10/hour of sleep. Both the use of only 10 seconds and the addition of only partial breath holds were inflationary. However, the consensus group decided that 10/hour was too high and reduced the threshold to 5/hour. This was profoundly inflationary rendering a massive portion of the population “diseased” and greatly decreasing the signal to noise..
The need to reduce to 5/hour was due to the fact that apneas occur in paroxysms (rapidly cycling clusters) so severe paroxysms of very long apnea could be present but fail to contain enough in number to meet the average of 10/hour rule. Here is an image of a paroxysm as detected by high resolution pulse oximetry.
This paroxysm has 17 apneas of duration 1-2 minutes in this image. However 17 ten second “baby apnea” would render the same result since all the AHI guessed gold standard method does is count as if these are simply coins of the same denomination.. This is what I discovered in 1998 when I identified severe paroxysms with long apneas in patients with less than the cutoff average of 10 apnea per hour. This is what caused me to examine the origin of the consensus and found it was all guessed,
While changing the cutoff to 5 ten second events /hr. captured most of the cases of severe but brief paroxysms it also captured a massive population of patients.
So looking at this process we see the mistake. The time series data were not analyzed to identify the different types of sleep apnea and the measurement of severity by counting threshold 10 second events 5-15 mild, 16-30 moderate, and greater than 30 severe were simply guessed and were not valid measurements of the pathophysiologic perturbations.
So here you can see just one of the problems with the guess. A patient with 35 ten second long apnea /hour is “Severe” while a patient 10 two minute long apneas per hour.is “Mild”. Simple counting renders profound errors in measurement of the complex diseases captured in the SET. .
So we see where they made the mistake. They bypassed the extensive research required to understand the diseases. Instead they guessed a set of criteria which effectively captured a SET of diseases and also captured very mild states of dubious significance. They then proceeded to perform 35 years of RCT using the SET. The massive research required to sort all of this out was never done. They moved directly to RCT with the guessed criteria and upon identifying cases which were missed by the criteria simply expanded the criteria.
This is the same process which was followed with sepsis in 1992. There was a desire to move directly to RCT of treatment. When the RCT were not reproducible they would simply amend the consensus. The sepsis consensus was amended 3 times over the past 30 years with the amendment in 2012 being highly inflationary. Protocols were built and are still applied using the guessed criteria even thought the RCT were negative. Pathological Consensus is a cancer on EBM and has increased skepticism of EBM among clinicians,
So your point in 2018 was exactly what was (and is) needed. This will require reform as participation in Consensus has replaced discovery as the best means to increase an academic’s citation value.
However we have to get past the talking stage. Something has to be done. We need real reform and the thought leaders show some evidence they are questioning their dogma. Its time to teach them. In fact most were taught this “Pathological Consensus” technique and they need help from statisticians focused on measurement to facilitate reform of the science..
3 Likes
Stipulating that improper “lumping” of patients with very different underlying pathologies for their sleep apnea might have contributed to many decades of non-positive RCT results, the next step would be to ask how researchers back in the 1970s and 80s should have proceeded.
It sounds like you’re saying that patients with the most profound and prolonged desaturations might be different, in important ways, from patients with frequent but shorter-duration and less severe apneas (?) I’m assuming that patients with central contributors to their apneas (e.g. brainstem CVA) were not lumped with patients with obstructive causes for their apneas for the purpose of conducting previous RCTs (?)…If they were lumped together, did this make sense physiologically?
Would it be reasonable to assume that the underlying distribution of prognoses for a group of patients with central apneas could be importantly different from the distribution of prognoses from a group of patients without evidence of central apneas (?) So would the next step have been to separate these two groups of patients and follow them over time to characterize their prognoses (i.e., their untreated clinical event rates e.g., CVA/MI/death)? If you agree, the next question to ask is whether that type of additional study would have been considered ethical at the time, given the demonstrated ability of CPAP to prevent apneas (at least the obstructive ones). Might ethical concerns around not offering treatment to already-diagnosed patients have precluded the types of “natural history” studies that could otherwise have informed and refined the inclusion criteria for future RCTs (i.e., RCTs designed to show “higher-level” benefits (e.g., improved survival/decreased CVA rates)?
So maybe sleep apnea is a bit of a special case, clinically speaking, when it comes to our ability to study it using “gold standard” methods like RCTs (?) The fact that treating OSA can produce benefits that manifest quickly (no more snoring, happier spouse, better blood pressure, weight loss, improved daily function) versus only after a prolonged time, perhaps worked against it in the long run. There’s clearly a spectrum of severity for this condition. And as is true for most medical conditions, we are most likely to be able to identify the intrinsic efficacy of a proposed treatment if we enrol patients with the worst prognoses- accruing more outcome events of interest tends to make the efficacy of the treatment, if present, easier to detect. Yet with sleep apnea, once we have diagnosed it, our hands are somewhat tied, ethically speaking. We can’t really leave these patients untreated for extended periods of time, in order to fully characterize their prognoses in the absence of treatment. A clinical catch-22…
2 Likes
I should have been more clear on this question.
Since the need is so critical, the best way to approach this is with a proposed Action Plan. This action plan relates to research where billions of dollars, countless careers and opportunities for discovery are being wasted. This does not apply to clinical medicine where the use of synthetic syndromes may be useful for quality improvement, flexible protocols, education and administrative use.
First Action
Recall the mandated use of pathologic consensus now.
** Administrators have replaced scientists, guessing has replaced research, and consensus has replaced discovery."
- This is restraining perhaps thousands of individuals or teams of researchers across the globe from discovering the actual conditions which have been improperly defined by pathologic consensus. We need to unleash these researchers. The mistake was to bridle and standardize their work using the same guessed (and wrong) measurements. The research of my team and so many others have been bridled (controlled) by administrative decree of the standard guessed erroneous measurements of pathological Consensus. This has to end now.
Research Step 1 In biological science meticulous and comprehensive collection and analysis of relational time series data pertaining to the phenomena under study. is required before any research can proceed. This is the step which was bypassed previously and replaced with pathological consensus, These retrospective data are presently available as Digital EMR and/or polysomnographic data.
Research Step 2 Separate the diseases by identification of sentinel (unique) relational time series patterns in the data to identify different diseases. Diseases may also be separated by clinical context such as a blood culture positive for a specific organism or a specific event such as perforated bowel or urinary tract infection.
Research Step 3 Identify diagnostic metrics (which may be the sentinel patterns). .
Research Step 4 Identify severity metrics which may be the diagnsotic metrics or the sentinel patterns. At least one morbidity and/or mortality should be a function of the Severity metrics
Research Step 5. Identify time series patterns which are present across multiple diseases and characterize the trajectories. These may be indicative of common pathways (treatment targets) .
Research Step 6 study the morbidity/mortality associated with sentinel patterns and seek surrogate metrics and biomarkers for all new diseases,
Research step 7 initiate RCT.
I look forward to further discussion.
Again, the first instant action "recall of pathological consensus" is required straight away.
1 Like
The identification of sentinel time series patterns and conversion of that into a statistically definable metric is fundamental to this effort. the former falls within my area of expertise but the latter requires expert statistician input.
Lets revisit the figure I produced earlier.
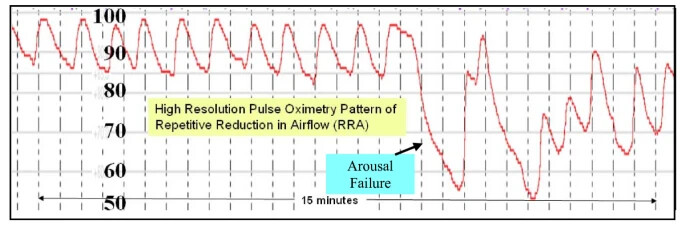
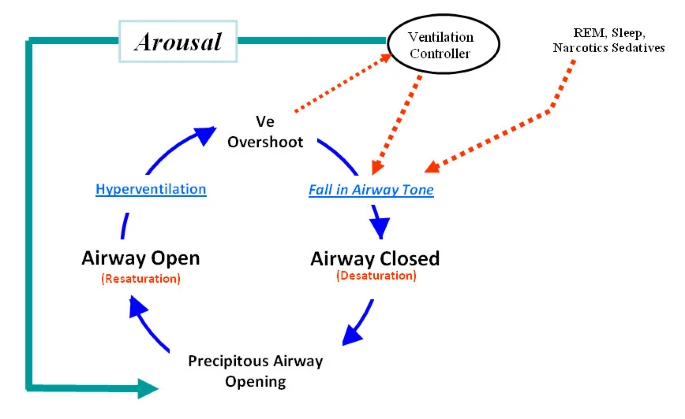
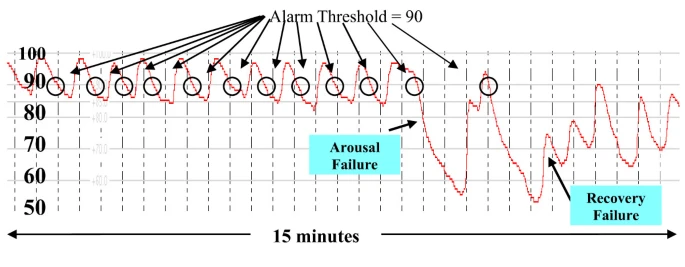
The first portion of the figure shows 11 rapidly cycling apneas of about 45 second duration with completer recovery between each apnea. This time series pattern is induced by typical reentry cycling (see cycling image below). The less regular pattern of second portion of the above figure is due to arousal failure which distorts the arousal dependent recovery cycling (see later pattern of above image) and the patient’s SPO2 falls to near death levels due to arousal failure. Note the fall past the former stable arousal threshold (stable for the first 11 apneas) and the severe fall to a very low nadir. Note the incomplete recovery despite severely low and life threatening arterial oxygen values (SPO2 values)
So there are three candidate sentinel patterns in the above figure and therefore we would hypothesize that three diseases are present one involving upper airway instability, another arousal failure and a third, recovery failure. The last two could be one disease. or an adverse drug reaction.
The next question is:
Are these sentinel patterns and, if they are, what is the best means to determine the incidence, clinical relationships, and the morbidity casually associated with each of these three sentinel patterns and to quantify each of them them for statistical analysis. This is hard work.
Here you see the AHI does not detect that three patterns are different since the long apnea are simply counted the same as the shorter apnea and the recovery pattern is not considered in the AHI. So a Dr. Referring a suspected case for polysomnography would learn the AHI but not the presence of arousal failure or recovery failure. .
This is a tough problem requiring expert statistical guidance with collaboration with an experts in time series analysis and clinical medicine. . The quantification of severity of time series patterns and conversion into a metric (surrogate) which can be processed statistically is complex work. .This is why the default is to simply guess thresholds and process them. But you see a few components of arousal failure and of recovery failure
-
- The duration of the apnea,
-
- the nadir of the SPO2,
-
- the area above the SPO2 curve,
-
- the magnitude and peak ratio of fall to recovery
- 5 the peak value of the recovery
-
- the global pattern of the paroxysm itself including duration of recovery between each apnea, regularity and onset pattern.
The point is that this, (not superficial analysis with "lumping’ similar looking diseases into into SETS and then guessing criteria for the SETS), is the process for identifying metrics of disease and then investigating the disease.
The same process would apply to the diseases which comprise sepsis. In all these cases genomic, proteomic and other data including time series data can be incorporated. Its a massive effort but each lab can contribute the the discovery of new sentinel patterns and metrics or massive trials can be funded for this purpose. The point is that the preliminary requisite work was not done they jumped right to (and still do) the derivation of synthetic syndromes from 20th century guessed criteria. Pathological Consensus is NOT an alternative to doing the work.
We asked for a grant to do this work for the synthetic syndrome “sepsis” and were declined because the view was that the work was not necessary as the criteria were already established (by the consensus group). The public deserves better for its funds then indefensible, oversimplified, Pathological Consensus. Centrally mandated erroneous measurements of Pathological Science of Langmuir,
Let us recall Pathological Consensus now and unleash the young researchers (the next generation) to get this work done.
1 Like
Thank you. I am sorry for the delay in responding. Do I understand correctly that the current differential diagnosis for the symptoms suggestive of obstructive sleep apnoea or hypopnoea is:
- No obstructive sleep apnoea or hypopnoea (Evidence: AHI <5 events per hour)
- Obstructive sleep apnoea or hypopnoea: (Evidence: AHI >4 events per hour)
- Other possible diagnoses
Are you are suggesting that there should be a more detailed differential diagnosis (with addition of the sentences in italics) to avoid missing Arousal Failure with recovery and Arousal and Recovery failure?:
- No sleep apnoea or hypopnoea (Evidence: AHI <5 events per hour but no prolonged apnoea pattern of arousal failure)
- Sleep apnoea or hypopnoea with: [A] Repetitive Reduction in Airflow / RRA (Evidence: AHI >4 events per hour without prolonged apnoea pattern of arousal failure) or (B) Arousal failure with recovery or (Evidence: AHI >0 of latter events of prolonged apnoea per hour) or (C) Arousal and recovery failure (Evidence: AHI >0 of latter events of very prolonged apnoea per hour)
- Other possible diagnoses
Some points:
- The treatment for RRA is an oral device or CPAP, weight reduction, etc. Should the treatment for Arousal Failure with recovery and Arousal and Recovery Failure be expected to be the same as for RRA?
- Do we know from observational studies how prevalent Arousal Failure with recovery and Arousal and Recovery Failure is in patients with symptoms suggestive of obstructive sleep apnoea or hypopnoea when the AHI is <5 events per hour and the AHI is > 4 events per hour? Is it possible to suspect Arousal Failure with recovery and Arousal and Recovery Failure clinically (e.g. with additional evidence of neurological dysfunction)?
- In order to establish the threshold for AHI where treatment for RRA provides a probability of benefit, I would do a study to estimate the probability of symptom resolution in a fixed time interval at different AHI values with no treatment or sham treatment (presumably a zero probability at all AHI values on no treatment) and on treatment. This might be done by fitting a logistic regression function or some other model to the data on treatment and on no treatment (when the curve might be zero for all values of AHI) and on treatment (when the probability of symptom resolution should rise as the AHI rises). Treatment should then be considered where the latter curve appears to rise above zero. This rise above the control curve may well happen at an AHI of 5 events per hour, or above or below 5 events per hour (e.g. 3 events per hour). This would be an approach setting a threshold based on evidence (as opposed to consensus guesswork).
- The above would apply to ‘RRA Obstructive Sleep Apnoea / Hypopnoea’. However for Obstructive Sleep Apnoea / Hypopnoea with Arousal Failure with recovery and Arousal and Recovery Failure the curve might be different with perhaps a clear probability of benefit at any AHI > 0. Note therefore that there may be a number of different AHI treatment indication thresholds created by a study of this kind. The symptoms alone might provide criteria for a diagnosis of ‘Clinical Obstructive Sleep Apnoea / Hypopnoea’, but for a ‘physiological’ diagnosis there may be 3 different criteria for (i) RRA, (ii) Arousal Failure and (iii) ‘Arousal and Recovery Failure. Each of these would also be sufficient to diagnose ‘Physiological Obstructive Sleep Apnoea / Hypopnoea’ (i.e. each might be a ‘sufficient’ criterion for the diagnosis) as well as prompting the doctor to offer treatment options. However, the probability of benefit from each treatment based from the logistic regression curve based on the AHI as a measure of disease severity and the adverse effects of treatment would have to be discussed with the patient during shared decision making.
- Although I consider Sleep Apnoea / Hypopnoea in my differential diagnoses in internal medicine and endocrinology and have some understanding of its investigation and management, I have never personally conducted Polysomnography or personally treated patients with CPAP etc., so please correct any misunderstandings. However, based on my work of trying to improve diagnostic and treatment indication criteria in endocrinology, the above is how I would approach the problem for Sleep Apnoea / Hypopnoea. I agree with you that this is a problem that needs close collaboration between clinicians and statisticians. The advice of statisticians such as @f2harrell or @stephen or someone similar in your area would be essential. I think that this type of work to improve diagnosis and treatment selection criteria is a huge growth area for future close collaboration between clinicians and statisticians. I am trying to encourage students and young doctors (and their teachers) to do this in the Oxford Handbook of Clinical Diagnosis, especially in the forthcoming 4th edition.
1 Like
I appreciate that your response is primarily designed to show a clinical/statistical approach to disentangling different diseases that have been, historically, lumped under one syndrome umbrella (e.g, “sleep apnea”). This is certainly very valuable. But for this particular condition, I’m not sure how much further ahead this disentangling would put us going forward.
I sense that sleep doctors are frustrated by systematic reviews which seem to call into question the value of treating sleep apnea. It costs a lot for the machinery needed to treat this condition properly. And I imagine that any time a payer can point to a list of “non-positive” trials as justification to withhold coverage for treatment, they are tempted to do so. This is presumably why the consequences of non-positive RCTs done historically in this field have been so frustrating for sleep physicians.
Lawrence suspects (I think) that one reason why RCTs of sleep apnea have not been able, historically, to show that treating apneas reduces a patient’s risk of death or cardiovascular outcomes, is that patients enrolled in previous trials should never have been lumped together in the first place. Using an arbitrarily-defined AHI cutoff, people with very mild underlying disease(s) causing their apneas were likely lumped together with patients with more severe/prognostically worse underlying disease(s), an approach to trial inclusion that was destined to produce “noisy” results (and therefore non-positive RCTs).
But even if sleep researchers wanted to rectify this problem going forward, knowing what we know today about the pitfalls of using syndromes as trial inclusion criteria, I really doubt that we’d have the ethical equipoise to do so (?)
Once we know that an existing treatment makes people feel and function better (and perhaps decreases the risk of motor vehicle accidents substantially…), it becomes ethically indefensible to leave them untreated for periods of time long enough to show benefits with regard to less common clinical outcomes (e.g. death, cardiovascular events, car accidents). This would be like denying people with chronic pain their analgesics for 5 years in order to show that those with untreated pain have a higher risk of suicide- unacceptable.
For the field of sleep medicine, this seems like a real dilemma (?) We have a strong clinical suspicion that if we were to design RCTs more rigorously, using patients with more homogeneous underlying pathology and worse (untreated) prognoses, we would be able to show significant benefits of treating their apneas with regard to “higher level” endpoints (mortality/cardiovascular events). However, because the treatment works so well for shorter-term patient-level endpoints, we are ethically prevented from designing the longer-term trials needed to show these higher-level benefits…
3 Likes