I have been reflecting further on this issue of whether we should estimate the risk differences from the risk ratio or odds ratio obtained from RCTs. I want to explain these issues to medical students, trainee doctors (and hopefully readers from other disciplines) in the final chapter of the forthcoming 4th edition of the Oxford Handbook of Clinical Diagnosis. I have had to conclude that neither the risk ratio nor odds ratio obtained from a RCT can be used to estimate the absolute risk reduction for different baseline risks. I used the data from the IRMA 2 study to fit logistic regression curves to the estimate risks of nephropathy in patients with different albumin excretion rates on placebo and treatment. The result is shown in Figure1.
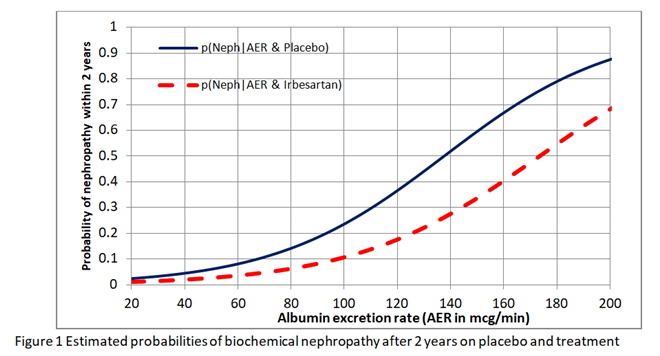
I then found the risk difference, the risk ratio and odds ratio at each point on these curves. As shown in Figure 2, neither the risk ratio nor the odds ratio was constant for all baseline risks provided by the placebo curve providing a counter-example for the constancy of both.
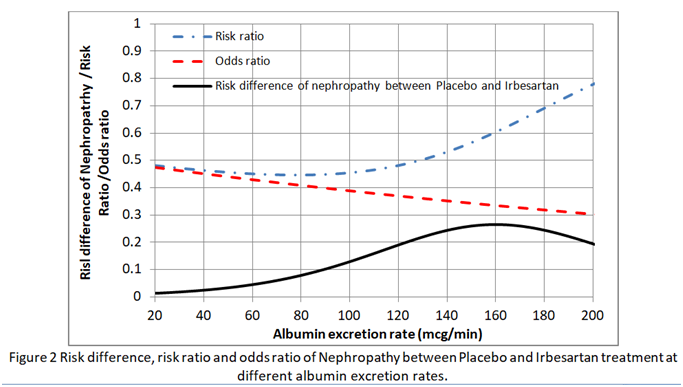
This implies that in order to estimate the absolute risk reduction, baseline data that predict risks of nephropathy have to be recorded during the RCT (e.g. as in the IRMA 2 study). Ideally the effects of covariates such as BP and HbA1c (that reflects blood glucose control) have to be minimised in the RCT so that the baseline risks are as low as possible (e.g. 0.01 to 0.02 at 20mcg/min in Figure 1). If the baseline risk in an individual patient is high (e.g. 0.5 at an AER of 100mcg/min due to for example additionally uncontrolled hypertension or uncontrolled diabetes), then the appropriate risk reduction (e.g. of 0.13 at an AER of 100mcg/min in Figure 2) is subtracted from this high individual baseline risk to give the new risk on treatment (e.g. of 0.5-0.13 = 0.37). Note that the risk ratio of 0.11/0.24 = 0.46 at an AER of 100mcg/min should not be applied to the total risk as this would exaggerate the effect of treatment by suggesting that the new risk was lower at 0.5x0.46= 0.23 as opposed to 0.37. This is common practice - applying risk ratios to total risk (e.g. when a risk ratio from RCTs on statins is applied to cardiovascular risks based on age, high BP, diabetes etc).
I would be grateful for comments.