Hello, I would like to calculate an SMD (Hedges’s g) from the results of a clinical trial. The following is taken from the FDA review:
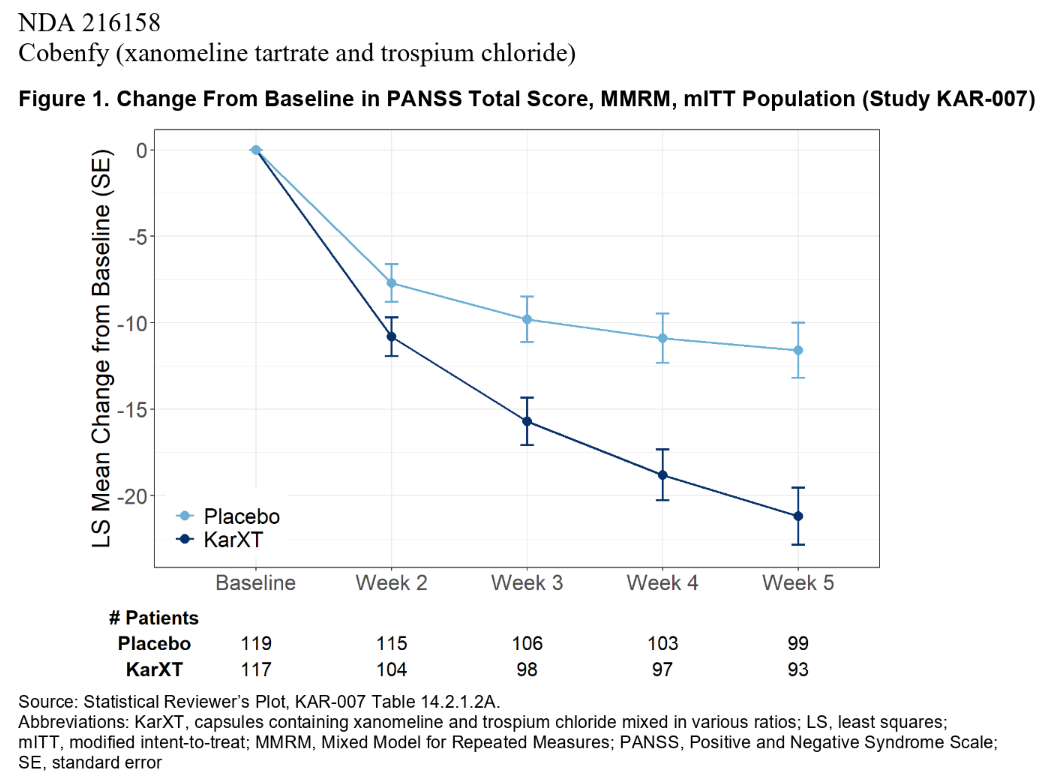
“The primary efficacy endpoint was the change from baseline in PANSS total score at Week 5. Efficacy analyses were conducted on the modified intent-to-treat (mITT) population, which consisted of all randomized subjects who received at least one dose of study drug, had a baseline PANSS assessment, and had at least one postbaseline PANSS assessment.
…
The primary endpoint was assessed using a mixed model for repeated measures (MMRM) with the change from baseline in PANSS total scores at Week 2, 3, 4, and 5 as the response variable, treatment, visit, and treatment-by-visit interaction as fixed effects, and site, age, gender, and baseline PANSS total score as covariates.”
My question is, which Ns should I use in the calculations? Baseline? Week 2 (the first on-drug study visit)? Week 5 (the final visit)?
Elaboration: The data provided at Week 5 are, for the drug and placebo groups: N (observed N), LS mean w/ SE, LS mean difference w/ 95% CI.
Planning to use Stata v.18 meta, which asks for N, mean, and SD, so I was planning calculating SE from SD and N (though again not sure which visit’s N should be used).
Unfortunately, that is the basis on which many of our drugs are evaluated and approved. Also bothersome is that change-from-baseline is also what’s shown in graphs in peer-reviewed journals. That little maneuver can make a trivial effect look rather large, at least to the intended readership.
No argument that regulatory agencies use flawed methods. (How about the fact that they fail to use meta-analysis and instead make drug approval contingent on the existence of 2 or more short-term trials that show statistical significance on the primary endpoint.)
However, to return to the original which-N question, is it answerable if we pretend that the sponsor used absolute, instead of change, scores?
I wonder if the FDA review reveals enough to support a fully Bayesian analysis capable of accounting for information lost to their bad analytical choices. Would you share a link to it?
Sure, here’s the link: https://www.accessdata.fda.gov/drugsatfda_docs/nda/2024/216158Orig1s000IntegratedR.pdf
This is for a drug approved just a couple of months ago for schizophrenia.
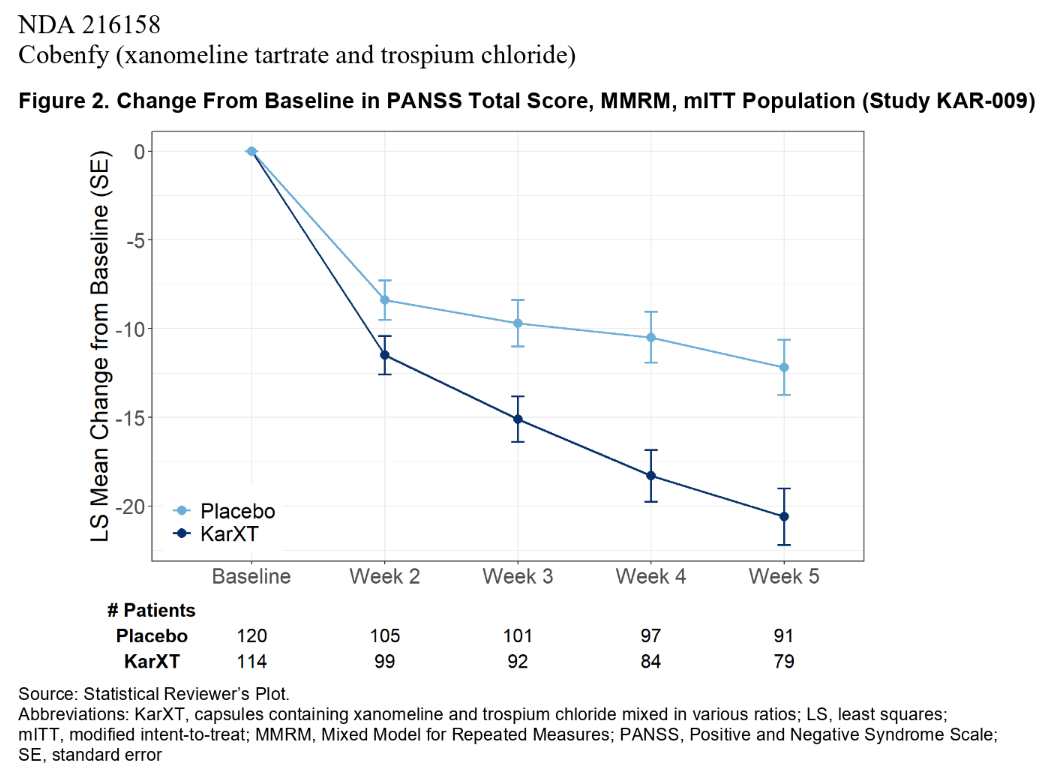
There were 3 DB-PC trials. In the 394-page PDF, the results of these trials can be found on pages 53, 58, and 64 (though for this last one, the baseline scores are missing, for some reason). Analyses on secondary endpoint are interspersed between those pages. Exploratory analyses can be found starting on page 299.
Pittelkow MM, Linde M, de Vries YA, Hemkens LG, Schmitt AM, Meijer RR, van Ravenzwaaij D. Strength of statistical evidence for the efficacy of cancer drugs: a Bayesian reanalysis of randomized trials supporting Food and Drug Administration approval. J Clin Epidemiol. 2024 Oct;174:111479. doi: 10.1016/j.jclinepi.2024.111479. Epub 2024 Jul 23. PMID: 39047916.
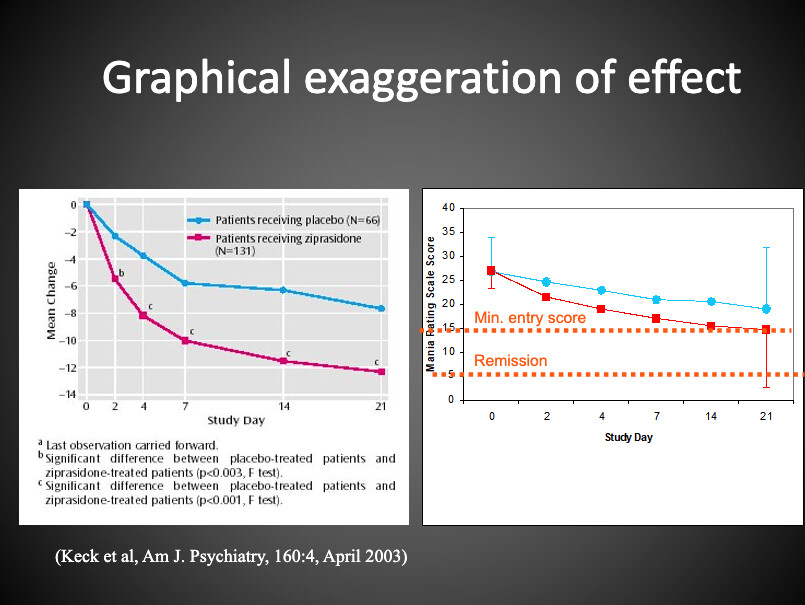
This is so frustrating and be seen as a coverup. By starting the graph at y=0 and not showing the actual baseline, the analysis does not inform us about whether those with big changes were the patients who started at one extreme or the other. Plot the raw data!
Plots like these might provide a reasonable basis for estimating a generative model that could serve as a ‘ground truth’ against which various analytical choices could be examined.
Here’s a graph I sometimes show in a course I teach.
The figure on the left is taken from an article about a drug approved for bipolar mania.
On the right side, I’ve re-plotted the data using absolute scores. It enables one to see that the mean of the drug group “Improved” to a point that still met entry criteria for the study and that it was far from the conventional threshold score for remission.
But apparently, journals are on board with showing the data in the more “impactful” way.
Thinking big here, what about the concept of a ‘shadow FDA’ — I’m drawing the term from the idea of a shadow ministry in the Westminster system of government — that was sufficiently trusted by payers to influence cash flows, and therefore practice? How hard would it really be, to build an institution more credible than whatever remains of an FDA operating under an antivaxxer’s leadership?
Edit: Just saw this piece by Timothy Snyder tooted by Boris Barbour. It sets the tone for what a community like this one could aspire to now. Rather than puttering around with this-or-that flawed approval, we might better aim to act in a concerted, systematic and strategic manner.