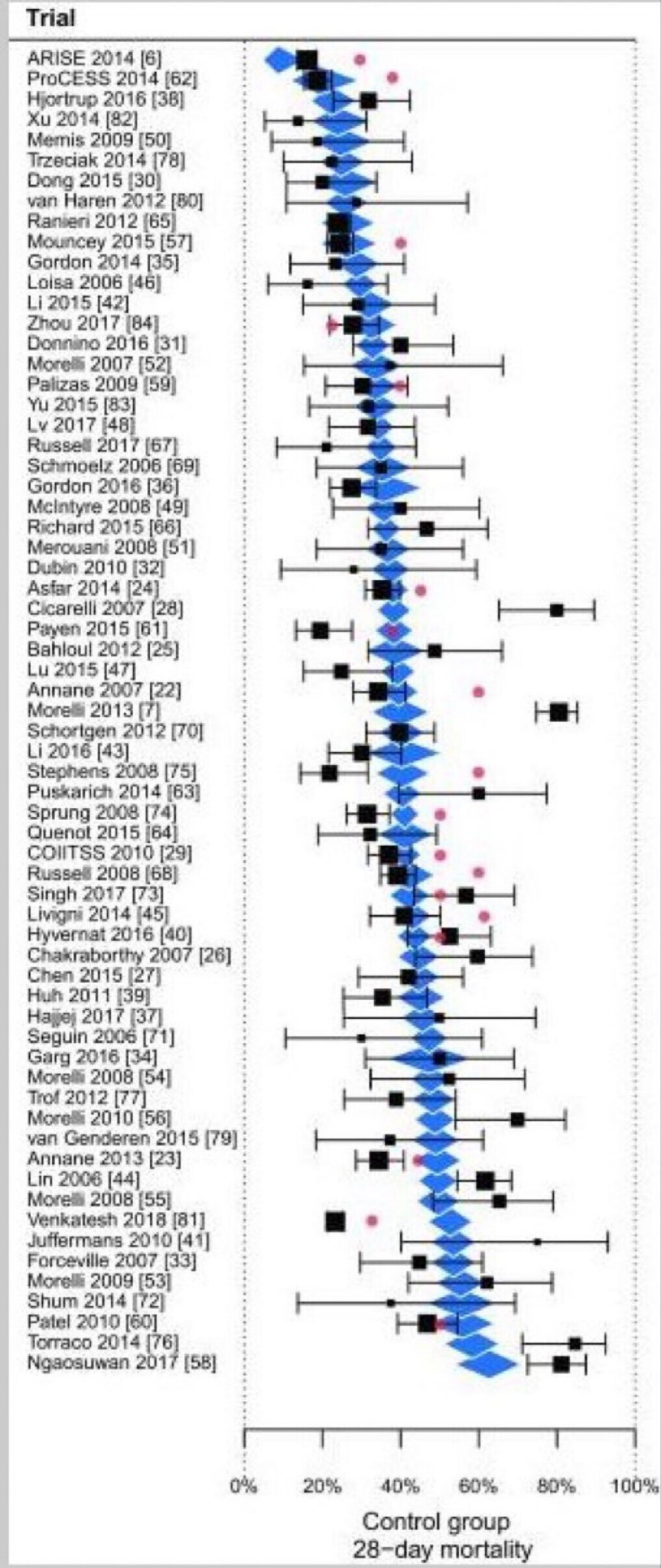
This is a discussion of the RCT of hydrocortisone treatment of severe community acquired pneumonia (CAP). As with many RCT in critical care medicine the results are conflicting in various RCT. The most recent RCT is from the highly touted REMAP CAP led by the editor in chief of JAMA suggested harm but this treatment is presently part of the treatment guidelines for CAP so this is a pressing issue.
Guidelines based on RCT that are subsequently reversed due to subsequent RCT showing harm are relatively common in critical care.
This thread seeks participation for the discovery of the cause of this the lack of reproducibility of perceived high quality RCT in critical care.
Here is the URL to the REMAP CAP
SpringerLink
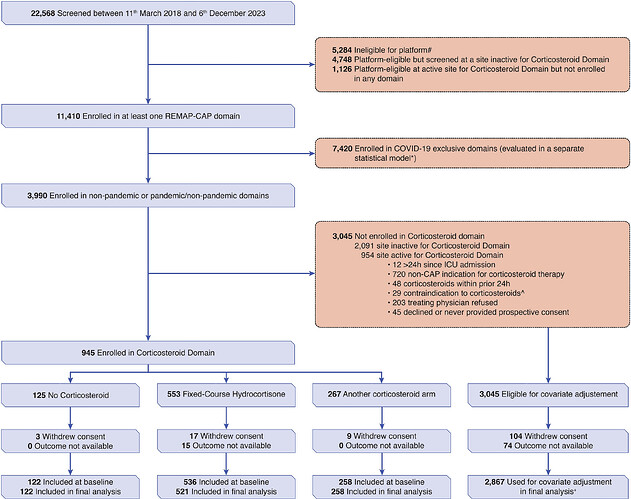
Effect of hydrocortisone on mortality in patients with severe…
Purpose To determine whether hydrocortisone improves mortality in severe community-acquired pneumonia (CAP). Methods In an international adaptive randomized controlled platform trial testing multiple interventions, adults admitted to the intensive…
and link to PDF
s00134-025-07861-w.pdf
Here is the link to CAPE COD


Hydrocortisone in Severe Community-Acquired Pneumonia - PubMed
Among patients with severe community-acquired pneumonia being treated in the ICU, those who received hydrocortisone had a lower risk of death by day 28 than those who received placebo. (Funded by the French Ministry of Health; CAPE COD…
And to the Cochrane meta analysis
This is a very important question in acute care as these severe pneumonia patients are often otherwise quite healthy.
RCT Reproducibly has been very low in the conditions of sepsis and ARDS. We thought that in Community acquired pneumonia (CAP) the signal was fairly strong. Yet CAP is a mixture of many very different diseases. For instance methicillin resistant staph aureus pneumonia is markedly different clinically from Pneumococcal pneumonia and even more pathophysiologically removed from influenza A pneumonia. These are all mixed under CAP.
I look forward to your thoughts. Right now I’m not sure whether to prescribe hydrocortisone or not in this setting.