Thanks to Frank Harrell for suggesting I bring this topic to the forum
As a clinical academic, intensivist and nephrologist my research is focused is on Acute Kidney Injury (AKI), particularly in the intensive care unit.
Reader of this forum will be aware that there are many concerns (1) with design and formulation of endpoints in AKI in clinical trials, a concern shared by myself and many researchers in the field. In particular, arbitrary dichotomisation of continuous data related to kidney function, implicit inclusion of change from baseline in AKI definitions without inclusion of acute level of kidney function at baseline & during disease, and lack of incorporation of temporal elements (duration and trajectory of kidney dysfunction which will best correlate with long term outcomes).
In addition, there are several biological and practical issues with AKI definition and severity scaling. These are related to the kinetics of serum creatinine with alteration of kidney function and muscle mass and well as data availability on pre-morbid kidney health and the effect of interventions such as dialysis.
These deficits impede the performance of suitably powered early phase studies and may account for previous failures to demonstrate benefit from interventions. There are also valid concerns that AKI (as defined by biochemical fluctuations and alteration in urine output) itself is not a suitably patient centred endpoint for pivotal studies
Our ambition is to develop a fit for purpose longitudinal ordinal endpoint for ‘acute kidney health’ to allow us to capture the burden of organ dysfunction over time. We believe such an outcome could capture the severity and fluctuating time-course of the disease episode and biologically best correlate with long term kidney health in recovery. It would also allow permit us to apply the Bayesian transition models described by Dr Harrell and colleagues in their 2024 Statistics in Medicine Paper,(2) especially by allowing the assessment of clinically interpretable estimands such as days of organ dysfunction over a clinically meaningful threshold.
We also believe AKI could be a great exemplar for these techniques given the depth of relevant longitudinal clinical data available, and the failure of existing approaches to deliver meaningful clinical results.
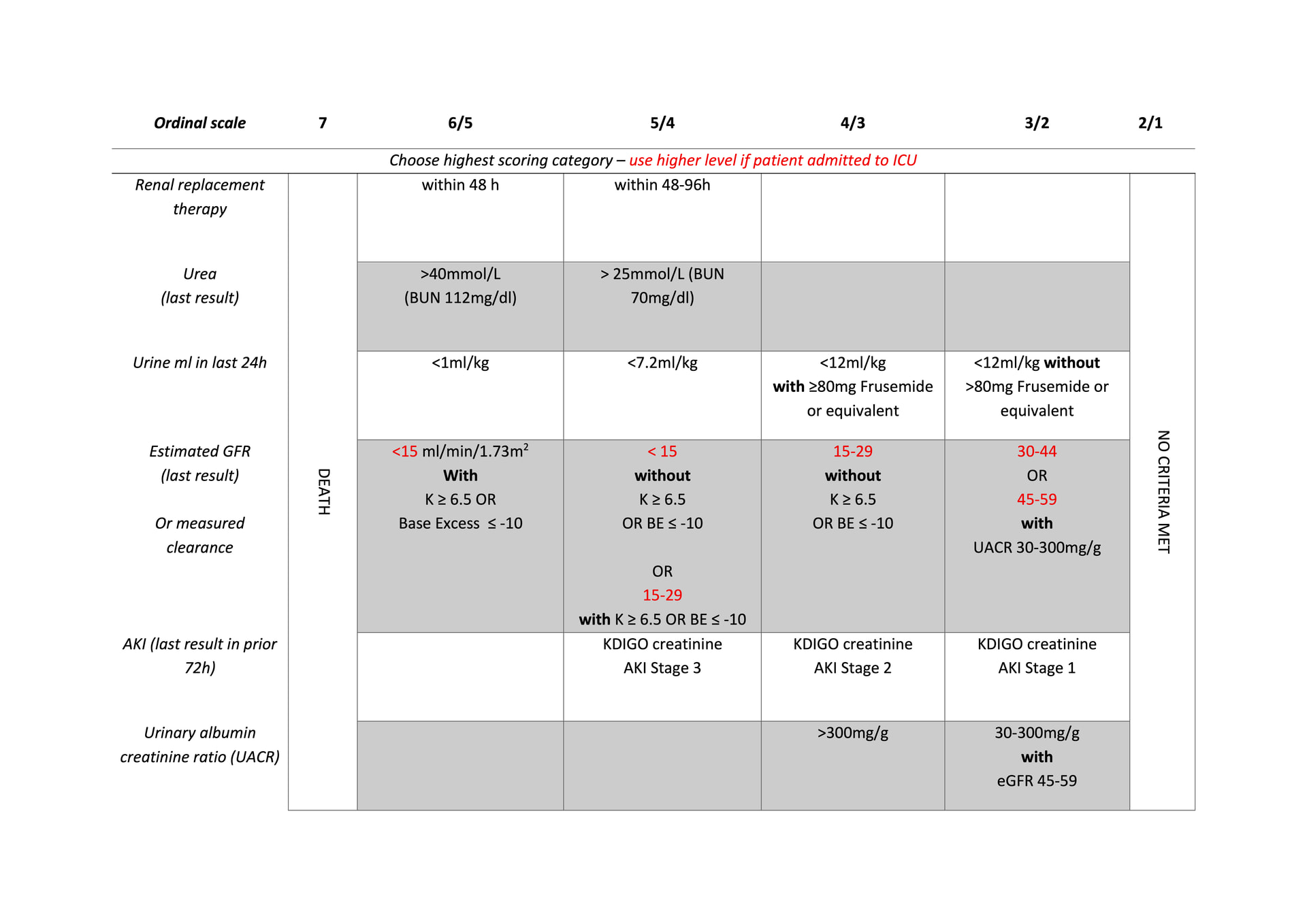
There are however many potential facets of kidney health which we might consider, allowing for several different domains to feed into the ordinal scale (ie biochemical values and urine output). Thus different points of the scale might be defined by absolute or relative changes in serum creatinine or other measures of kidney function, severity of low urine output, other biochemical parameters such as serum urea/BUN and use of kidney replacement therapy and death as an absorbing state.
We are working on a paper which outlines a proof-of-concept ordinal kidney health definition, however we plan to more robustly define the clinical elements by expert consensus and will be seeking patient input (as to relevance and importance) and pharma industry input regarding incorporation into studies and regulatory aspects.
While, to retain interpretability within our existing clinical concepts, our ideas for a kidney health definition do include existing ‘problematic’ aspects of AKI - including dichotomised severity levels and relative changes - we feel these may be offset by the longitudinal assessment of a more granular ordinal scale over time, as well as the incorporation of several paths to achieving a given scale level (absolute levels of kidney function tests as well as acute changes). However, this is something we will have to carefully consider in our formal development process.
The strength of our group is a network of experts with a lot of clinical experience and physiological understanding of acute kidney health and also access to data from existing clinical studies for sense-testing and preliminary analyses prior to prospective use. However, while we have been able implement some test analyses with our proof-of-concept scale, to take this forward as a group of clinician-researchers we obviously need formal expert statistical support and collaboration.
As a preliminary we seeking some advice on whether this community feels that ‘acute kidney health’ is a suitable setting for designing and applying a longitudinal ordinal outcome and specifically:
- If the more complex formulation of several routes to achieve the same ordinal scale level is going to be problematic analytically? - as compared to a simpler scale of level of organ support (as has been implemented in respiratory disease).
- If to what extent do we need to worry about abrupt transition of states which might inform the scale design?
- What are the problems in carrying forward observations or other imputation in case of missing data in one component on a given day?
Finally, we are wondering if there are any potential collaborators or expert commentators that might be interested in helping us with the work going forward.
Many thanks for your interest!
John Prowle for the LOKI (Longitudinal Outcome in acute Kidney Injury) Investigators
Some illustrations
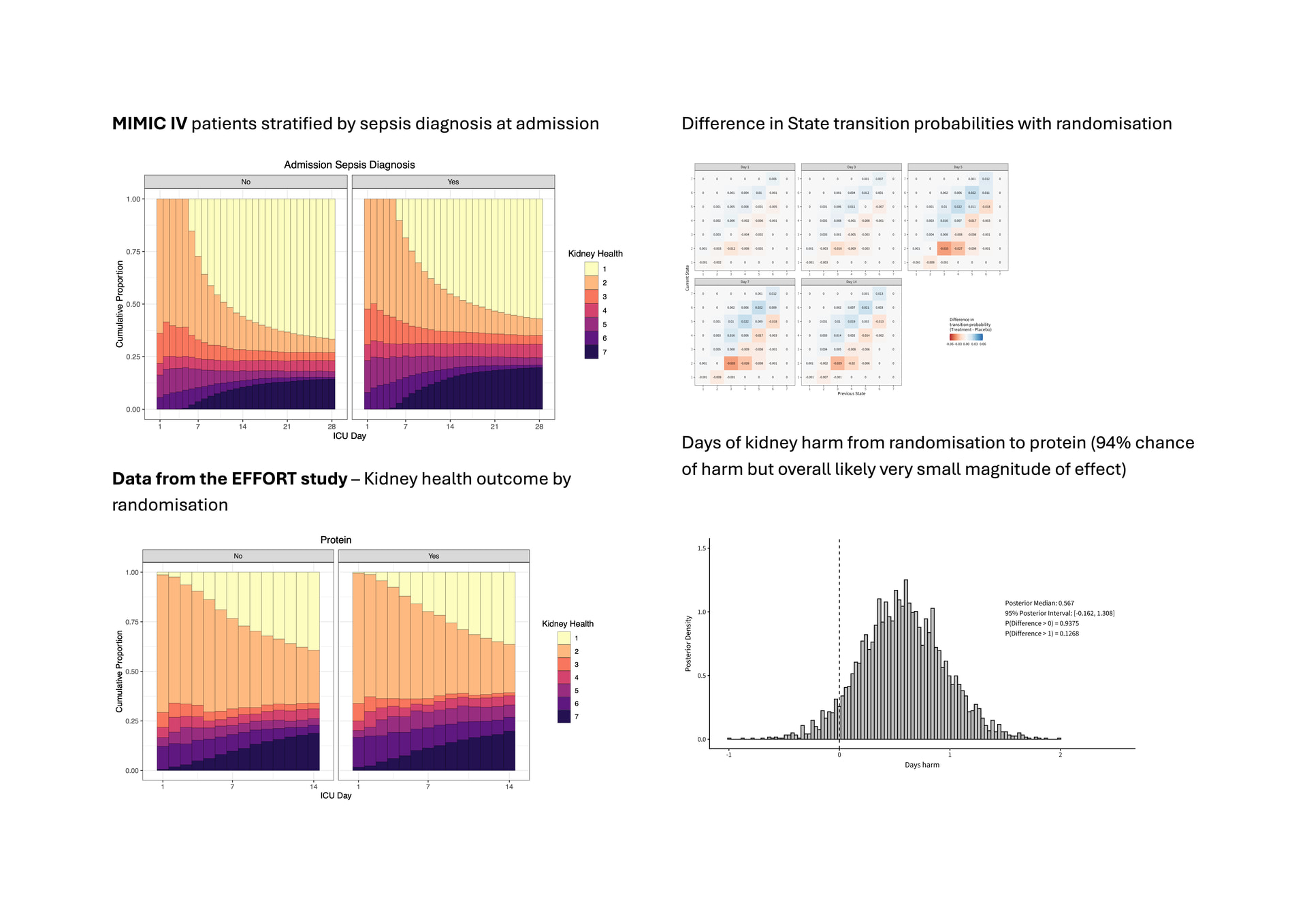
Our draft ordinal scale of 7 levels is based on recent use of dialysis/RRT absolute and acute relative changes kidney function test, urine output on a given day, blood urea albuminuria and other diagnostic biomarkers, location of care (in ICU), and death as an absorbing state.
Based on the published codes we have been able to implement our draft ordinal outcome definition in an observation dataset (16609 adults with ICU length of stay ≥ 5days without end stage kidney disease from the MIMIC IV database) as well as data from an ICU clinical trial of a potentially kidney-injurious intervention (protein supplementation). I attach these as examples. The effect in the randomised study is very small (in keeping with our knowledge of the study findings more generally) and this is presented on as a demonstration of implementation of the transition model not at all as a finalised result. (Apologies for size but only one upload allowed)