OpenAI has created ChatGPT, a “chat generative pre-trained transformer” that has received extensive worldwide attention. ChatGPT has been tested in a variety of situations and has been able to achieve passing levels in professional school exams among many other things. To learn about how good ChatGPT is for answering questions about statistics, especially about choosing statistical attacks to problems, I tested it with some difficult questions that require experienced statisticians to understand. Thanks to my cardiologist colleague Dan Mark at Duke University for putting me onto this.
I started with a very difficult question: What are the main issues in analyzing compound endpoints in clinical trials? Here is the response.
Analyzing compound endpoints in clinical trials can be challenging for several reasons:
- Complexity: Compound endpoints are often a combination of multiple, often disparate, outcomes, making the analysis more complex and difficult to interpret.
- Bias: Compound endpoints can be subject to selection bias, as the endpoints are often chosen based on convenience or availability, rather than on the basis of clinical importance or relevance.
- Lack of homogeneity: Compound endpoints can be heterogeneous, as they may consist of outcomes that have different scales, distributions, and levels of variability. This heterogeneity can make it difficult to combine the endpoints into a single summary measure.
- Multiple testing: Compound endpoints often require multiple hypothesis tests, which can increase the risk of type I errors and false positive results.
- Power: Compound endpoints can reduce the power of the study, as they can dilute the effect size of each individual endpoint, making it harder to detect meaningful differences between treatment groups.
- Interpretation: Interpreting the results of a compound endpoint analysis can be challenging, as it is difficult to determine the relative importance of each individual endpoint and how they contribute to the overall result.
- Clinical Relevance: It may be difficult to determine the clinical relevance of a compound endpoint, as it may not reflect the specific outcomes that are most important to patients or clinicians.
Overall, these issues highlight the importance of careful consideration and planning when designing and analyzing studies with compound endpoints. It may be more appropriate to focus on individual, clinically relevant endpoints and perform multiple, well-designed studies to address different aspects of the research question.
Item 5 is wrong, and the answers ignore the existence of Bayesian methods, but overall I admit this is pretty impressive. The system wasn’t “smart” enough to know that when endpoint components are recurrent events, most approaches to analysis of compound events ignore occurrences after the first, which loses power.
Next I asked: In a clinical trial with multiple types of outcome events, if each event satisfies the proportional hazards assumption with regard to the treatment effect does the time until the first event satisfy the prorpotional hazards assumption? Here’s the answer.
The answer to whether the time until the first event satisfies the proportional hazards assumption in a clinical trial with multiple types of outcome events depends on the nature of the events and the relationship between them.
If each individual event satisfies the proportional hazards assumption with regard to the treatment effect, it does not necessarily mean that the time until the first event will also satisfy the proportional hazards assumption. This is because the proportional hazards assumption is concerned with the relationship between the hazard function and the treatment effect, and the hazard function for the time until the first event is likely to be different from the hazard function for each individual event.
In order to assess whether the time until the first event satisfies the proportional hazards assumption, it is necessary to examine the relationship between the hazard functions for each individual event and the treatment effect. If the hazard functions for each individual event are proportional to each other, then the time until the first event may satisfy the proportional hazards assumption. However, if the hazard functions are not proportional, it may be necessary to consider alternative models or strategies for analyzing the data.
Overall, it is important to carefully consider the assumptions underlying the analysis and to perform appropriate sensitivity analyses to assess the robustness of the results to potential violations of the proportional hazards assumption.
Again a good answer, and the answer was better than when I first posed the question 4 days previously.
Next, How does one deal with time intervals with missing data when analyzing time until an event in a clinical trial?
There are several methods for dealing with time intervals with missing data when analyzing time until an event in a clinical trial:
- Complete Case Analysis: One of the simplest methods is to exclude individuals with missing data, and perform the analysis only on individuals with complete data. However, this method can result in substantial loss of information and can lead to biased estimates if the missing data is not missing completely at random.
- Last Observation Carried Forward (LOCF): In this method, the last observed value is carried forward for individuals with missing data. This method is simple and easy to implement, but it assumes that the missing data is missing at random, which is often not the case in clinical trials.
- Multiple Imputation: This method involves creating multiple imputed datasets by using statistical models to estimate missing values, and then combining the results from each imputed dataset. This method allows for more accurate estimation of the treatment effect and reduces the risk of bias associated with complete case analysis or LOCF.
- Inverse Probability Weighting: This method involves weighting each individual based on the likelihood of their data being missing, and then using these weights in the analysis. This method allows for more accurate estimation of the treatment effect and reduces the risk of bias associated with complete case analysis or LOCF.
- Joint Modeling: In this method, a statistical model is used to jointly model the time-to-event and the missing data process, allowing for a more comprehensive and accurate estimation of the treatment effect.
The choice of method for dealing with missing data in a clinical trial will depend on the nature of the missing data and the objectives of the analysis. It is important to consider the assumptions underlying each method, and to perform appropriate sensitivity analyses to assess the robustness of the results to potential violations of these assumptions.
This is not so good. I was looking for something related to interval censoring or using a state transition model with gaps in data collection (missing longitudinal records).
Next: What is a rational alternative to making a binary decision about the inclusion of an interaction term in a regression model?
There are several alternatives to making a binary decision about the inclusion of an interaction term in a regression model that are based on a more rational and systematic approach. These alternatives include:
- Model Selection Criteria: Instead of simply including or excluding an interaction term, one can use model selection criteria, such as AIC or BIC, to choose the best-fitting model that balances goodness of fit with parsimony. These criteria will penalize models with a large number of parameters and reward models that fit the data well with a smaller number of parameters.
- Model Comparison: One can compare the performance of models with and without the interaction term, using techniques such as cross-validation or bootstrapping, to determine which model is more accurate and robust. This allows for a more nuanced evaluation of the impact of the interaction term on the overall performance of the model.
- Prior Knowledge: If prior knowledge is available about the relationship between the variables, it can be used to inform the decision about whether to include an interaction term. For example, if it is known that the relationship between two variables is non-linear, an interaction term may be necessary to capture this non-linearity.
- Partial F-test: A partial F-test can be used to test the significance of an interaction term in a regression model, taking into account the uncertainty in the estimates of the other parameters. This allows for a more nuanced evaluation of the impact of the interaction term on the overall fit of the model.
Overall, these alternatives to a binary decision about the inclusion of an interaction term in a regression model provide a more systematic and data-driven approach, taking into account the uncertainty in the estimates and the overall performance of the model.
Except for 3. this is not very good at all. I was looking for the use of a Bayesian prior on the magnitude of the interaction effect.
How does a Bayesian t-test differ from a frequentist t-test?
A Bayesian t-test and a frequentist t-test are both statistical tests used to determine whether there is a significant difference between two groups. However, the two tests differ in the way they approach the problem of hypothesis testing.
- Definition of Probability: A frequentist t-test is based on the frequentist definition of probability, which defines probability as the long-run frequency of an event in a large number of trials. In contrast, Bayesian t-test is based on the Bayesian definition of probability, which defines probability as a degree of belief in an event based on prior knowledge and evidence.
- Prior Information: In a Bayesian t-test, prior information about the population parameters is incorporated into the analysis. This prior information can be in the form of prior distributions, which are updated based on the observed data to provide posterior distributions. In a frequentist t-test, there is no consideration of prior information, and the analysis is based solely on the observed data.
- Interpreting Results: In a frequentist t-test, the results are interpreted in terms of p-values and confidence intervals. A p-value represents the probability of observing the data if the null hypothesis is true, and a low p-value is taken as evidence against the null hypothesis. Confidence intervals provide an estimate of the population mean with a specified level of confidence. In contrast, a Bayesian t-test provides a posterior distribution for the population mean, which is a probability distribution representing the uncertainty in the estimate.
- Flexibility: Bayesian t-tests are more flexible than frequentist t-tests, as they allow for the incorporation of prior information and can handle more complex models with multiple parameters. However, this flexibility can also make Bayesian t-tests more difficult to interpret and more prone to bias if the prior information is incorrect.
Overall, the choice between a Bayesian t-test and a frequentist t-test depends on the problem at hand and the available data. If prior information is available and can be incorporated into the analysis, a Bayesian t-test may be preferred. If prior information is unavailable or unreliable, a frequentist t-test may be a more appropriate choice.
Not too bad. I was looking for something like “With Bayesian t-tests one can easily allow for non-normality and unequal variances, and interpretation of posterior probabilities is more intuitive than that of p-values.”
In the next example one sees a problem in “leading the witness”. How does exploratory data analysis benefit the calculation of confidence intervals?
Exploratory data analysis (EDA) can be beneficial for the calculation of confidence intervals in several ways:
- EDA can help identify outliers and other data issues: By visually inspecting the data, researchers can identify outliers, missing data, or other issues that may affect the analysis. This can help to ensure that the confidence intervals are calculated based on clean, accurate data.
- EDA can help identify patterns and trends in the data: By looking at the data in different ways, researchers can identify patterns and trends that may indicate the presence of underlying relationships or associations. This information can be used to inform the choice of statistical models and methods used to calculate the confidence intervals.
- EDA can help identify appropriate transformations: Some distributions of the data may not be well-suited for certain statistical methods. Exploratory data analysis can be used to identify appropriate transformations of the data that will make the data suitable for the methods used to compute the confidence intervals.
- EDA can help identify the assumptions of the statistical models: Many statistical models have assumptions that must be met for the model to be valid. EDA can help researchers identify whether these assumptions are met and if not, how to adjust the model accordingly.
- EDA can help to establish the sample size: By exploring the data, researchers can make an estimate of the sample size required to achieve the desired precision of the estimates, which can help to avoid underpowered studies.
Overall, EDA can help researchers to better understand their data and identify any potential issues that could affect the calculations of the confidence intervals. By identifying these issues, researchers can make more informed decisions about the methods and models they use to calculate the confidence intervals, which can lead to more accurate and precise estimates.
No warnings about distortion of statistical inference were made. Contrast those answers with the answers to What is the harm in doing exploratory data analysis before computing a confidence interval?
Exploratory data analysis (EDA) is an important step in the data analysis process, as it allows researchers to understand the characteristics of their data and identify potential issues or patterns before conducting formal statistical analysis. However, it’s important to be aware that EDA can lead to bias in the estimation of confidence intervals if not done carefully.
One of the main issues with performing EDA before computing a confidence interval is that it can lead to data snooping bias. Data snooping bias occurs when researchers look at their data multiple times, and each time they look, they make additional adjustments or decisions based on what they see. This can lead to overfitting of the data and an overestimation of the precision of the estimates.
Additionally, EDA can lead to multiple testing problems, which can inflate the type I error rate (i.e. false positives) and make the confidence intervals less accurate. This is because EDA often involves looking at many different variables or subsets of the data and testing many different hypotheses, which increases the likelihood of finding something by chance.
Another problem with EDA before computing a confidence interval is that it can lead to selection bias. For example, if researchers perform EDA and decide to exclude certain outliers or observations, it can lead to biased estimates of the confidence interval.
Therefore, it’s important to be aware of these potential biases and to conduct EDA in a way that minimizes their impact. This could include, for example, using techniques such as cross-validation, or using a pre-specified plan for data analysis that minimizes the number of decisions that are based on the data. Also, it’s important to report all the steps of the EDA that were performed, and the rationale for each decision made.
Once harm was mentioned, a much better answer was given.
Is a p-value a direct evidentiary measure or an indirect measure?
A p-value is an indirect measure of evidence. It provides a measure of the strength of the evidence against the null hypothesis, but it does not provide a direct measure of the evidence for or against the alternative hypothesis.
A p-value is calculated as the probability of observing a test statistic as extreme or more extreme than the one observed under the assumption that the null hypothesis is true. A small p-value suggests that the data provides strong evidence against the null hypothesis and in favor of the alternative hypothesis. However, it is important to note that a low p-value does not necessarily mean that the alternative hypothesis is true; it simply indicates that the evidence against the null hypothesis is strong.
In conclusion, while p-values are a commonly used tool in statistical hypothesis testing, they should not be relied upon as the sole measure of evidence in a study. Other factors, such as the study design, the sample size, and the magnitude of the effect, should also be considered when interpreting the results of a study.
This is an excellent answer, although I was hoping that the Bayesian alternative would be mentioned.
My conclusions so far:
ChatGPTis worth trying- For some classes of complex statistical methodology questions it is functioning as well as a trained statistician who has very little experience
- It is subject to bias from leading questions
- It doesn’t provide references nor a clue of where it’s getting its information
- It is more suitable for helping people avoid big mistakes in choosing statistical methods than in giving them advice on how to choose the most suitable methods
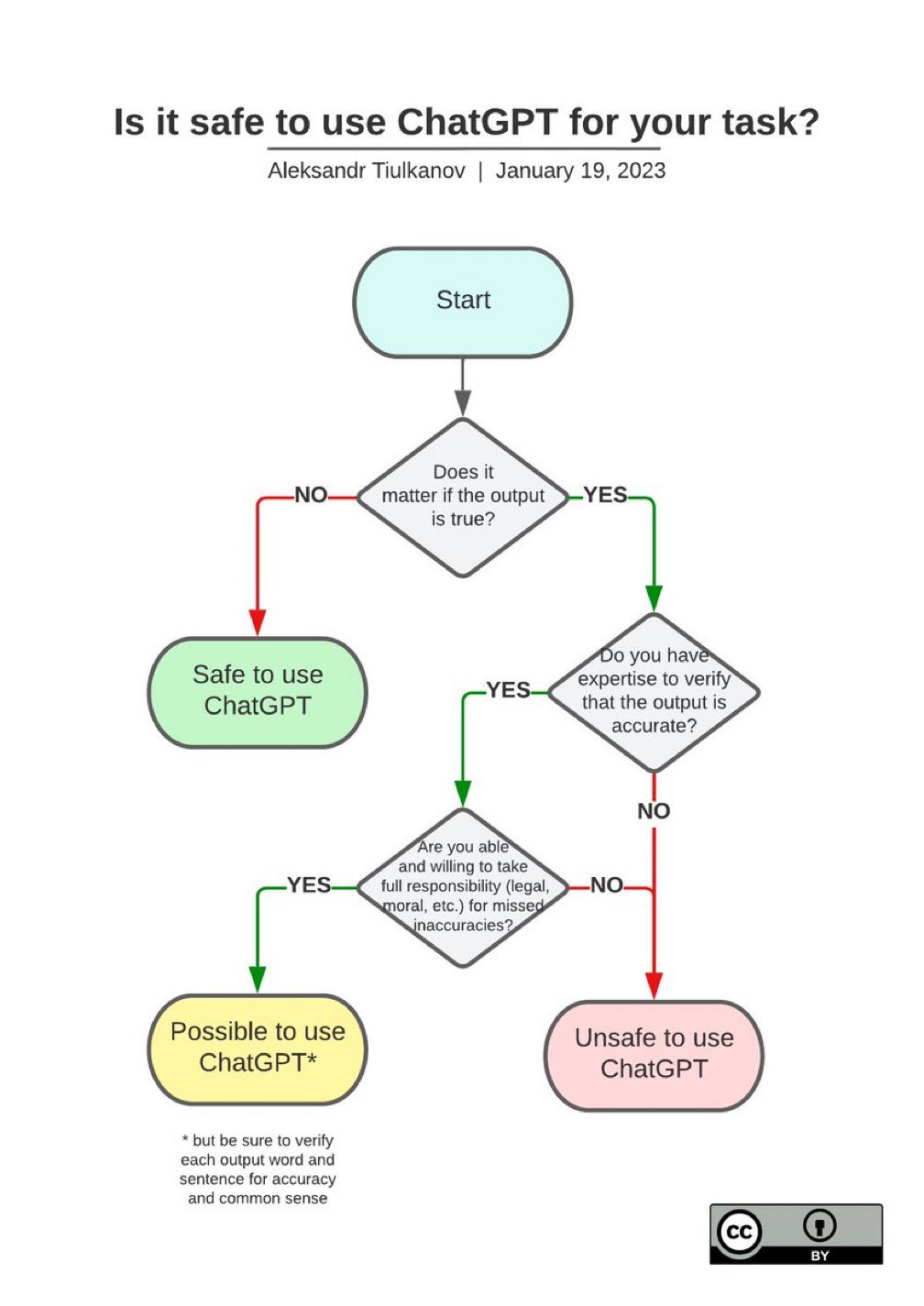
One would do well to take the advice of Aleksandr Tiulkanov who has created an excellent flowchart about safe use of ChatGPT: