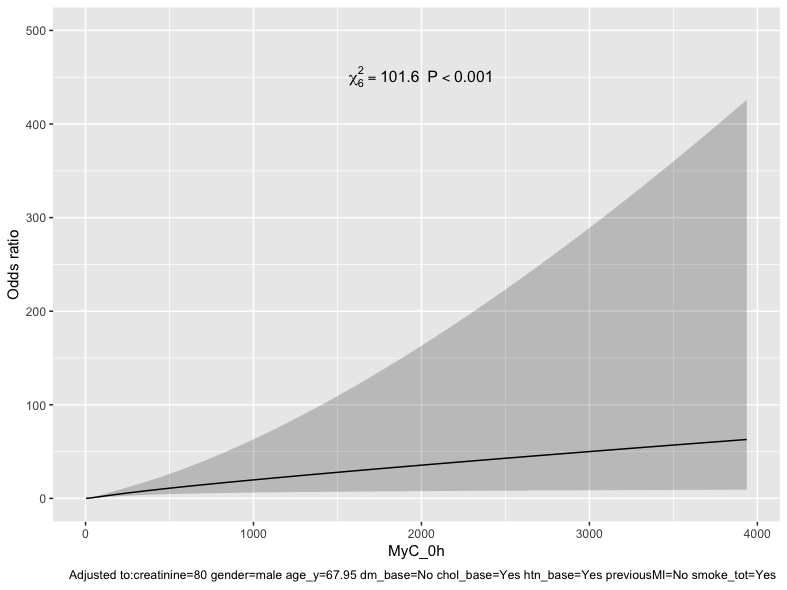
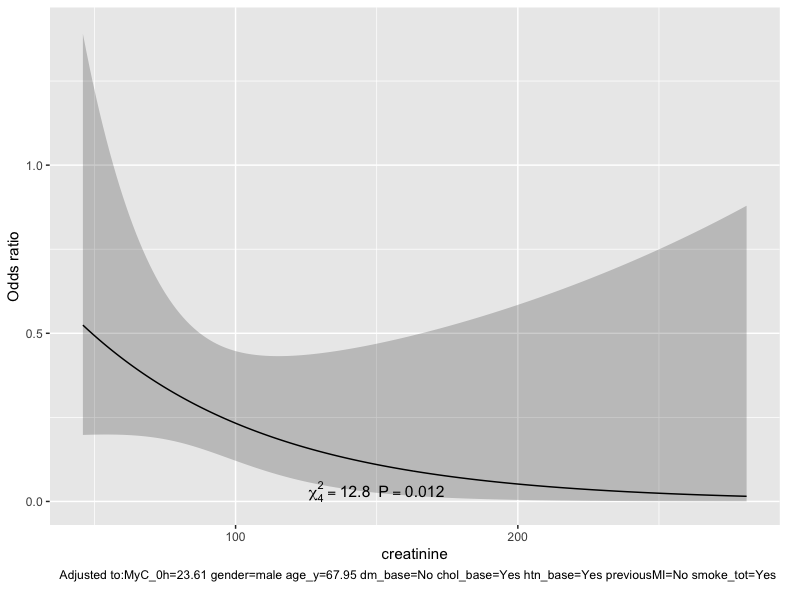
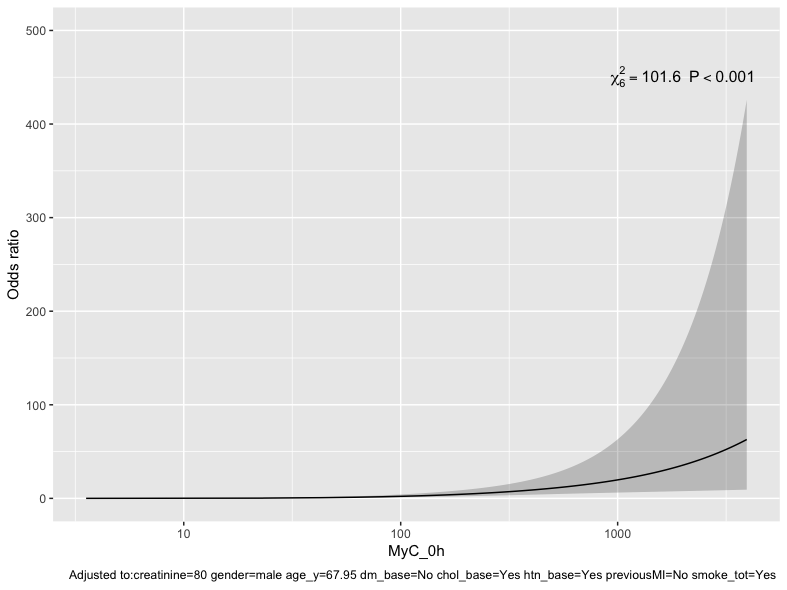
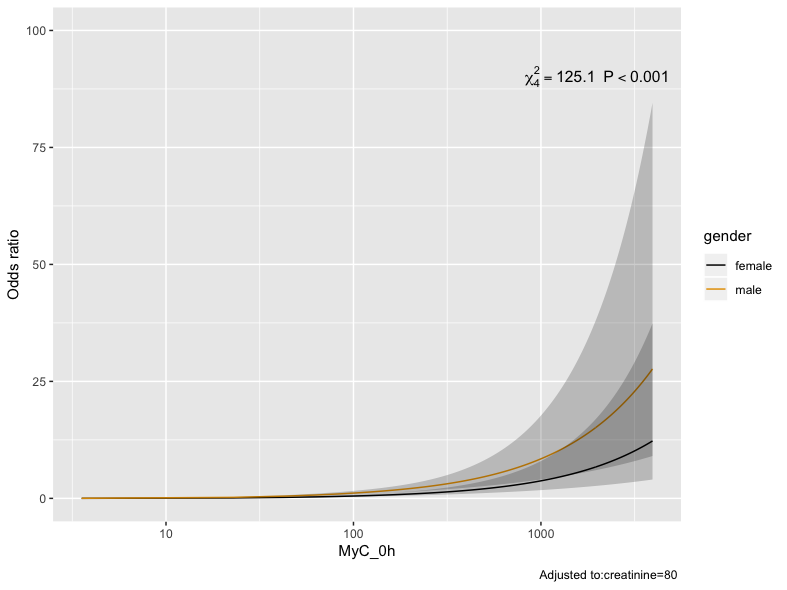
What I haven’t figured out yet is how to incorporate the interaction in a model using restricted cubic splines - as the argument rcs(MyC_0h, 4) * creatinine as used before when using splines does not compute:
singular information matrix in lrm.fit (rank= 13 ). Offending variable(s):
MyC_0h'' * creatinine MyC_0h''
Error in lrm(AMI ~ rcs(MyC_0h, 4) * creatinine + gender + age_y + dm_base + :
Unable to fit model using “lrm.fit”
It’s not clear if you can assume that the interaction is linear in creatinine. But allowing splines on both would make the numerical problems worse. You might use a restricted (in this case completely linear) interaction with rcs(x, 4) + creatinine + rcs(x, 4) %ia% creatinine.
When performing a fastbw on the models, the factors in the final model are still the same - MyC, creatinine & gender. Why do you think it is that I can’t use the interaction term in a model written as follows:
> lrm(AMI ~ rcs(log(MyC_0h), 4) + creatinine + rcs(log(MyC_0h), 4) %ia% creatinine + gender, data=dat)
singular information matrix in lrm.fit (rank= 8 ). Offending variable(s):
MyC_0h'' * creatinine
Error in lrm(AMI ~ rcs(log(MyC_0h), 4) + creatinine + rcs(log(MyC_0h), :
Unable to fit model using “lrm.fit”
Interesting! Did you try to plot the spline fits? I always find that helpful in understanding these kinds of models.
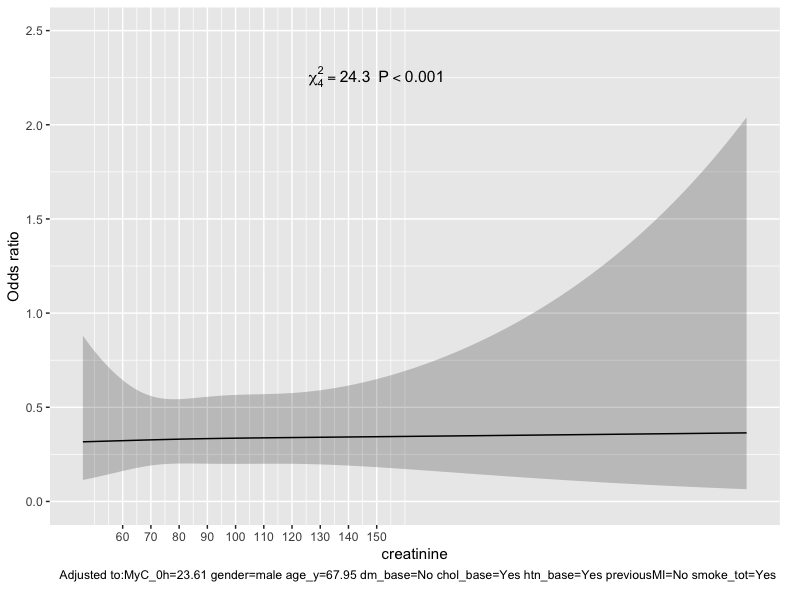
If you plot the fit from the model Frank suggested, one thing you might also try is to fit this model: x + rcs(creatinine , 4) + x %ia% rcs(creatinine, 4)
and also plot that fit. Assuming there are not numerical problems it would give you some idea of how non-linear the creatinine variable is. I’m sorry I’ not familiar enough with rms to explain the error code you are getting.
Peronsally, I don’t use automatic selection algorithms at all anymore. I think its better to make decisions on variable inclusion/exclusion based on your expert knowledge. DAGs can be helpful although I am but a novice with them myself. @f2harrell I’m curious your thoughts on this?
Also interesting that this model does not compute unless there are other variables included in the model. I’m working on trying to figure out why this is…
Did you plot this fit too? I’d be curious to see that.
You could try reducing the rcs df to 3 to see if that makes numerical issues eaier. (sorry I missed it above if there is a specific reason your are using df = 4)
Ok wow that stays very linear even though it has the freedom to deviate from linear - in contrast to the biomarker! Seems rcs(log(MyC_0h), 3) is the better choice.
So what you could also plot for the model: AMI ~ rcs(log(MyC_0h), 3) + creatinine + rcs(log(MyC_0h), 3) %ia% creatinine
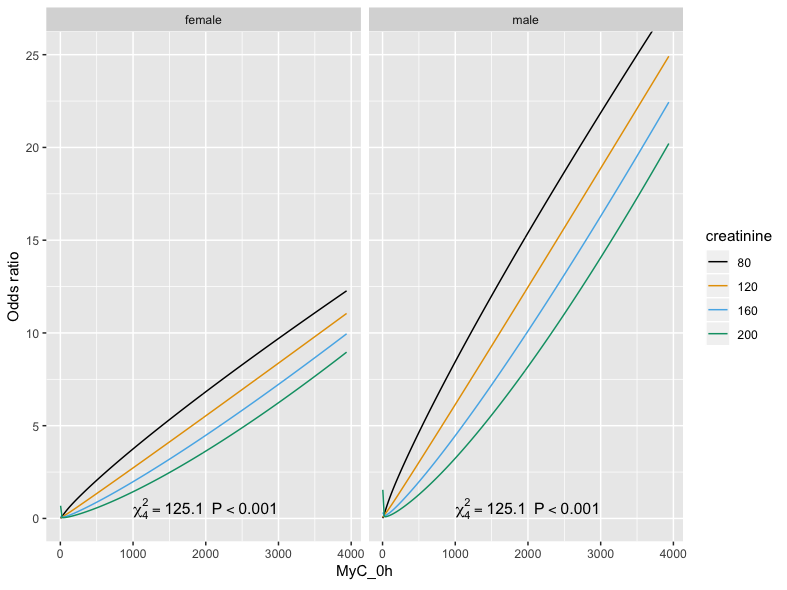
make a plot for OR vs MyC_0h at different creatinine values, eg. Cr = 80, 120, 160, 200. Then if you want to also include gender you could facet_wrap by gender giving you a male and female facet for example.
To give you an idea - this is from a presentation I gave previously - the coloured lines are each at a certain fixed value for a continuous variable that interacts with the x varaible (which includes a spline):
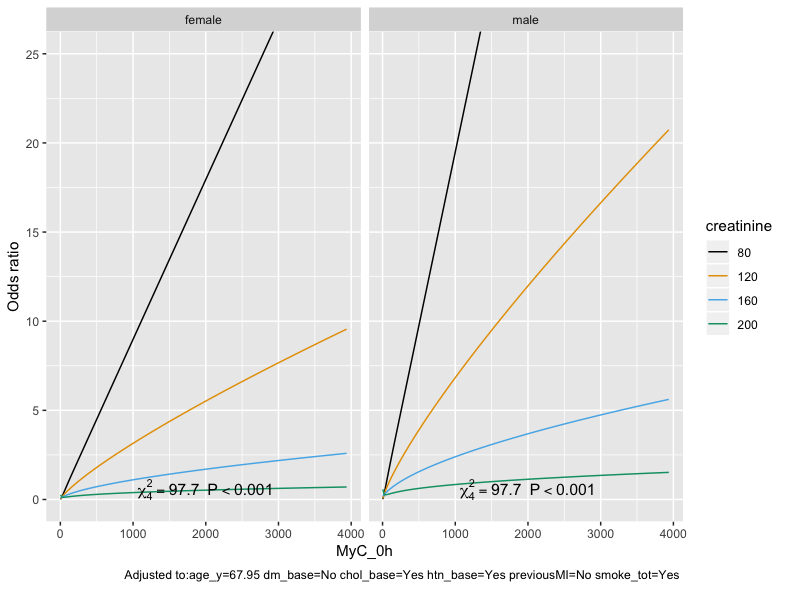
Thanks. CIs overlap in the following plot, so omitted but that should reflect the relationship - and is a nice way to present the interaction and gender-specifics:
Wow big male to female differences.
Which model is behind this - its more linear than I expected (although - maybe not having gender in the model caused some of the apparent non-linearity in the graphs earlier).
I picked those values arbitrarily - you could just use 3 more spaced out ones if you want.