The BBR Course Notes §§14.4–5 thoroughly impeach change-from-baseline analysis. I had previously avoided the practice simply on regression-toward-the-mean grounds and because @f2harrell said so. But I find myself really astounded to (re?)discover how comprehensive and multifaceted a case can be made against it!
That said, I think sometimes the best way to discourage bad practices is to provide positive examples of the good practice. This may be especially true when we are reaching out to non-statisticians who may have real, pressing interests in promoting sound statistical analyses. (FYI, this question is prompted by this petition from lymphoma patient advocate Karl Schwartz.)
Can anyone point to exemplary analyses of QOL, especially in the clinical trials literature, that avoid change-from-baseline pitfalls?
10 Dec 2019 Addendum
In case it helps focus this question a bit better, I’d like to articulate formally the aims of Karl Schwartz’s petition linked above, as I’ve come to understand them after some further discussion with him. As I now understand, the problem originates with the use of surrogate endpoints such as progression-free survival (PFS) in regulatory decision-making. The reliability of such surrogates as predictors of meaningful clinical benefit is debated. From a biostatistical perspective, a natural remedy for such a ‘noisy’ univariate outcome would be to augment it to obtain a multivariate outcome that incorporates other information as well. The petition asks specifically that QoL information derived from patient-reported outcomes (PROs) be incorporated together with PFS in regulatory decisions. Interestingly, this placing of PFS and QoL on a similar footing (i.e., as components of a multivariate outcome) further underscores the correctness of comparing QoL endpoints between arms, as opposed to QoL ‘changes’ from baseline in individuals.
5 Likes
The ISCHEMIA study QOL analyses led by John Spertus are role models for how to do this, avoiding change from baseline and using Bayesian models to get more interpretable and accurate results. We’ll have to wait for a paper or preprint to see analysis details.
I have a perfect example but of how a proper analysis yields a much different (and more correct result) but it uses proprietary data so I can’t show it. But here’s a description. The Hamilton-D depression scale is often used in antidepressive drug development. Change from baseline to 8w is a very common outcome measure even though (1) this disrespects the parallel-group design and (2) difference in Hamilton-D were never shown to be valid patient outcome measures that can be interpreted independent of baseline.
I re-analyzed a pharmaceutical industry trial using the best available statistical approach: a distribution-free semiparametric proportional odds ordinal logistic model on the raw 8w Ham-D value, adjusted flexibly for the baseline Ham-D by incorporation of a restricted cubic spline function with 5 default knots. Here was the result and ramifications:
- Unlike the linearity required for valid use of a change score, the relationship between baseline Ham-D and 8w Ham-D was highly nonlinear. The shape was similar to a logarithmic function, i.e., very high baseline Ham-D can be “knocked down” and become a moderate or low 8w Ham-D. There was a flattening of the curve starting at Ham-D=22.
- This function shows that an excellent therapeutic effect may be obtained in severely depressed patients.
- It also shows that an average change score, which assumes not only linearity but a slope of 1.0, is highly misleading. The excellent potential for high baseline Ham-D to get lower will be averaged in with the less amount of change from lower baseline Ham-D patients. The resulting average change from baseline underestimates treatment effect in severely depressed patients and overestimates. The average change from baseline may not apply to any actual patient.
- The proper ANCOVA respects the goal of the RCT: if patient i and patient j both start with a Ham-D of x but are randomized to different treatments, what 8w Ham-D are they likely to experience?
- ANCOVA using ordinal regression completely handles floor and ceiling effects in patient outcome scales.
8 Likes
This criticism in particular should prove immediately accessible and intuitively appealing to the patient-advocate perspective that motivated my question. I can’t think of any more devastating challenge to any biostatistical procedure, in fact, than that it bears no relation to the concerns, outcome, etc., of any individual patient. I conjecture that one could make this the axis on which a comprehensive critique of change-from-baseline turns.
2 Likes
This can be said for any endpoint (PFS, OS, response) right?
To clarify my advocacy:
-
PRO instruments standardized to compare fatigue, physical pain,… overall QoL across studies
(so the subjective experiences is given directly by patient (apart from stressful consults)
not misinterpreted, or under-reported by study doctors)
- in future: included in all studies with ePRO
to improve safety (timely reporting of changes that require supportive or ER care)
a study to be referenced later showed improved OS associated with this practice.
-
As an required consideration in studies using surrogates (PFS) as primary endpoint.
Especially relevant to RCT tests of continuous use and maintenance protocols
(Is potential gain in PFS (often modest) worth the additional toxicity experienced on a daily basis?)
-
Not typically to be used in isolation as the basis for approval.
-
Cutoffs for clinically significant differences in PRO scores.
… to inform regulatory and clinical decision-making.
-
Reporting of PROs should standardized - done in a way that fosters patient understanding as a decision aid. Example: Do I want to pay for an expensive treatment (in some cases bankrupting my family) to possibly gain x months, when the treatment is unlikely to improve (or impairs) my QoL on a daily basis?
1 Like
Based on my understanding, all of those things apply, and none of them are satisfactorily addressed by computing change from baseline. Gain in Y needs to come from comparing Y in treatment A patients to Y in treatment B patients, adjusted for baseline to gain power/precision.
3 Likes
@davidcnorrismd, I felt that the ARAMIS trial did a great job analyzing QOL outcomes.
2 Likes
They did this:
The secondary end points were overall survival, time to pain progression (defined as either an increase of ≥2 points from baseline in the score assessed with the BPI-SF questionnaire or initiation of opioid treatment for cancer pain, whichever occurred first)
This is very problematic, although challenging to deal with optimally when the score is combined with other endpoints.
For quality-of-life variables, an analysis of covariance model was used to compare the time-adjusted area under the curve (AUC) between groups, with covariates for baseline scores and randomization stratification factors. The least-squares mean and 95% confidence interval was estimated for each group and for the difference between the groups.
The first part of this is good, if change from baseline was not computed. But to assume Gaussian residuals in a regular model for this kind of response variable is tenuous. The variable calls for an ordinal regression.
2 Likes
Copying from the protocol.
I wonder if anyone can comment on:
- the 16 week assessment schedule for QoL input? (seems arbitrary? bias that may result?
- cutoff for significance: 10 points in FACT-P total score compared with baseline.
- weakness/strength of using ePROs providing near real time reporting
6.3.3.6 Health-related quality of life
The mean of the screening and day 1 (pre-treatment) values will serve as baseline for QoL.
6.3.3.6.1 FACT-P
QoL will be assessed using a disease-specific FACT-P questionnaire completed by the patient
(Appendix 5a). FACT-P will be assessed at screening, day 1, week 16 and at the end-of-study
treatment visit during the study treatment period.
Patients will be defined as having total QoL deterioration, if they experience a decrease
of 10 points in FACT-P total score compared with baseline.
6.3.3.6.2 PCS subscale of FACT-P
QoL will be assessed using prostate cancer-specific subscale of the FACT-P questionnaire
(PCS subscale of FACT-P) completed by the patient (Appendix 5b).
PCS will be assessed every 16 weeks until the end of the follow-up period.
Patients will be defined as having QoL deterioration, if they experience a change of 3 points
in PCS compared with baseline.
6.3.3.6.3 EQ-5D
QoL will also be assessed using a generic EQ-5D questionnaire completed by the patient.
Mobility, self-care, usual activities, pain/discomfort, and anxiety/depression are each assessed
on 3-point categorical scales ranging from “no problem” to “severe problem” (Appendix 6)
EQ-5D will be assessed at screening, day 1 and every 16 weeks until the end of the follow-up
period.
Patients will be considered to have deterioration in overall QoL, if they experience a
deterioration of 0.06 points compared with baseline at 2 consecutive assessments.
1 Like
Further to Frank’s criticism of the change-from-baseline flaw in this trial, we see the additional problem that interpretation of the trial relies on classification (disguised via the word “defined”) according to this change. This implicates the classification-vs-prediction distinction that I consider the single most revelatory thing I have learned from Frank. (It’s one of those things that becomes so much a part of your thinking that you need to go back in memory to the moment you first encountered it, to remember just how nontrivial it is!) Here is a tweet of his, underscoring the vital importance of this distinction for person-centered health care:
https://twitter.com/f2harrell/status/972094453845561349
1 Like
My layman’s understanding - feel free to correct me: risk prediction generally involves biomarkers or other characteristics that point to an increased probability of adverse or beneficial outcomes. Indeed this is valuable (the heart of personalized medicine) but also illusive, right? What predicts a bad outcome requiring large correlative studies and prospective validation. When validated they can be integral to eligibility of a given study - you can’t do the study without the assessment of the biomarker.
Here I take the definition of QoL deterioration as a classification of an outcome based on the net change in participant status - a way to measure good or bad results from taking the study drug.
To the basic questions, using change from baseline is a disaster, then dichotomizing (“responder analysis”) that is a double disaster. Misleading, arbitrary, means different things to different patients, power loss, … Details are here.
1 Like
I was calling attention to a definition of QoL deterioration used in the study cited by a member here as a good example of QoL / PROs used in a study.
My goal is to identify models for RCT that include PROs as adjuncts to the commonly used primary surrogate endpoints (PFS). This so the outcomes (only patients can report) such as fatigue and pain which determine how well people live can be captured more objectively and accurately and considered with greater confidence in regulatory assessments.
To be clear: I am not advancing a method of analysis for PROs.
Some investigators are asserting that gains in PFS from continuous use (and maintenance) protocols also improves QoL. Since PFS gains so often do not lead to improved OS, I feel this assertion needs to be tested.
Added 12.18 Responses I’m thankful for, but I don’t have the background to understand them adequately. The message seems to be:
- QoL domains (PROs for pain and suffering) cannot be reliably compared within a study comparing radio-graphic endpoints - sufficient to justify inclusion as a study endpoint. Study size sufficient for PFS comparisons are insufficient to compare the impact of continuous treatment needed to maintain remission on QoL.
I haven’t learned yet if sampling methods may be helpful to the stated goal - if real time capture of QoL domains with ePRO instruments can mitigate the concerns cited. Unlike radiographic tumor response, pain and suffering may be attributed to social or financial factors which PRO instruments may not account for (although they can and should).
1 Like
Toward the end of the “Details are here” link in Frank’s brief post above is this example of prognostic counseling that could well be based on QoL / PRO data of the kind you hope to collect, Karl:
What is an example of the most useful prognostication to convey to a patient? “Patients such as yourself who are at disability level 5 on our 10-point scale tend to be at disability level 2 after physical rehabilitation. Here are the likelihoods of all levels of disability for patients starting at level 4: (show a histogram with 10 bars).”
Notice how the conversation is rooted in (statisticians would say, “conditioned on”) the patient’s current situation. Also, see the difference (-3) in disability levels never enters the discussion; the focus is placed on health states and their meaning. (Consider the modified Rankin scale as a scoring system with meaningfully defined health states, but for which score differences are meaningless.) Finally, uncertainty about the final outcome is conveyed with a histogram.
I wonder if starting from a regulatory standpoint has obstructed your view of the issue, in something like the way that regarding drug dependence as a law-enforcement (as opposed to health-care) problem does. Why not start with the desired prognostic counseling script, and work backward to the trial designs that will support that script?
3 Likes
sorry, do not know what you mean here: desired prognostic counseling script?
I desire independent (having no COIs, evidence-based) regulators to include the totality of effects when deciding if a treatment based on a surrogate meets standard for marketing approval - provides poor, good, excellent evidence that I will live longer or better than some other treatment. I don’t want this left to doctors based on poorly informed opinions and conflict of interest (ASP portion of full price of drug and who-knows-what other relationship with drug companies. I’m for raising standards for surrogate-based approvals which often do not improve how long people live , which adds financial stress to the side effects of the treatments. Leaving this to MD interpretation invites poorly designed studies, errors, a return to medicine by sales pitch – a return to the Wild West.
Assumption: issues with the fidelity of change from the baseline and regression to mean (which I poorly understand) will be balanced out by random allocation to study arms even if individual signals are suspect. Marginal difference in changes from baseline can be interpreted as not significant.
1 Like
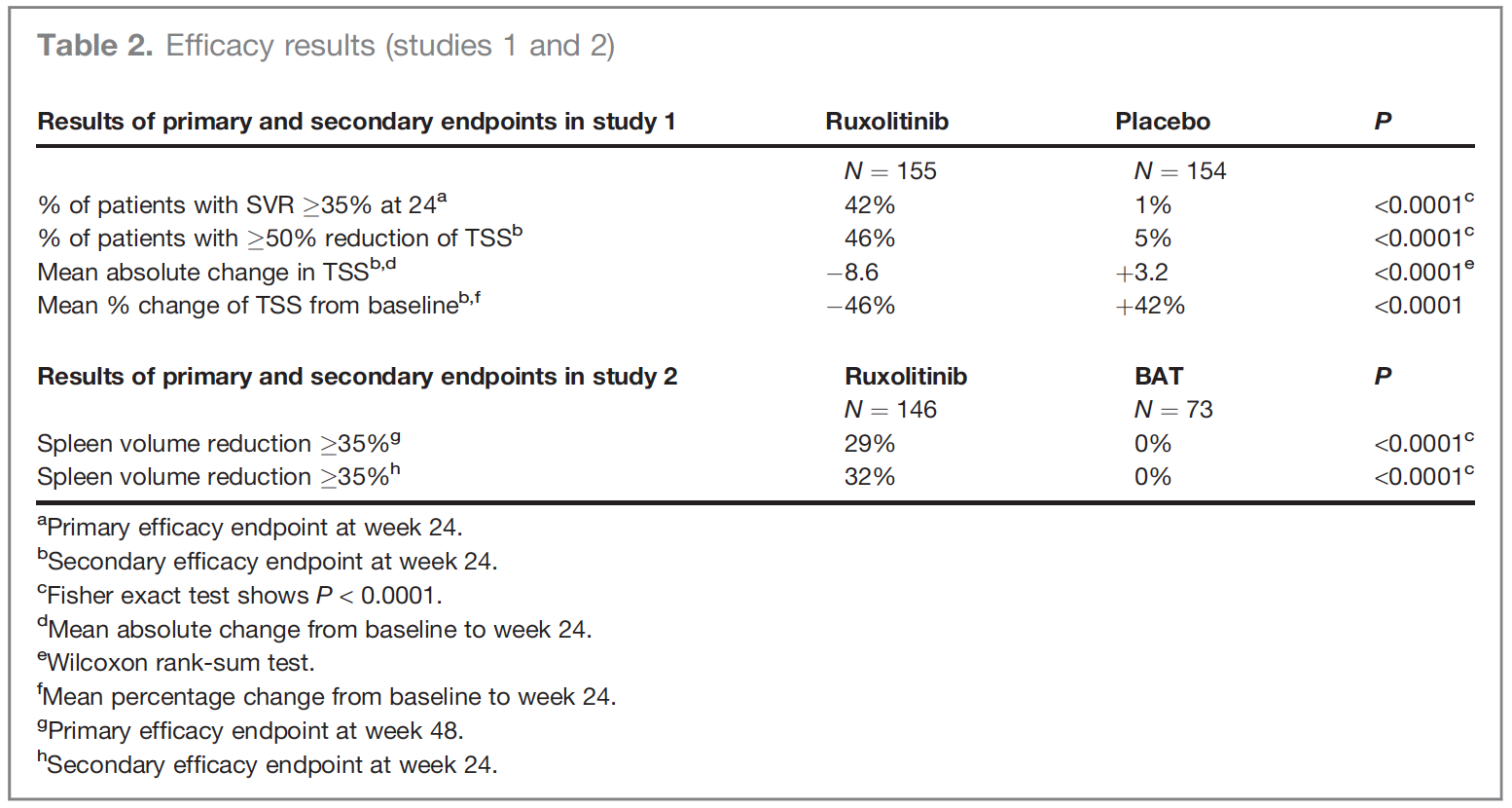
I’ve come across this FDA approval, which employed several of the objectionable methods including change-from-baseline and percent change. The comparison nevertheless seems persuasive, in light of opposite signs of changes. Presumably, more efficient use of the data would have enabled a smaller trial?
Deisseroth A, Kaminskas E, Grillo J, et al. U.S. Food and Drug Administration approval: ruxolitinib for the treatment of patients with intermediate and high-risk myelofibrosis. Clin Cancer Res. 2012;18(12):3212-3217. doi:10.1158/1078-0432.CCR-12-0653 PMID 22544377
4 Likes
Yes, that approach loses power in addition to losing interpretation. FDA has been far too lenient in the use of change from baseline.
3 Likes
Thank you, David. Based on a sampling of studies including QoL PROs in the Results published to ClinicalTrials.gov, the change from baseline approach seems the standard method for randomized controlled trials.
1 Like
There may be a need to categorize QoL PRO objectives in order to develop the most appropriate study design. In this study the PROs are clearly related to the disease status and serves as a response to treatment surrogate.
For systemic cancers areas of presentation vary widely and therefore the level of pain (if any pain exists yet from the disease) cannot be organ-specific for that QoL PRO.
Might eligibility for organ-specific PRO-centered studies need to pre-specify the discomfort level as an eligibility criteria – such as for bone pain in cancers that cause that symptom?
My area of concern is based on personal experience with systemic indolent lymphoma, which does not typically lend itself to organ-specific PRO outcomes and can be asymptomatic before and after induction therapy. Here a controversial standard approach (widely adopted but not yet showing a QoL or Survival benefit) is maintenance Rituxan after Rituxan-based chemo. Another controversial approache is lenalidomide as maintenance - again, without evidence that patients live longer or better. Here the PRO question is does the long term use of an agent that extends the duration of the tumor response worth the side effects of the drug? Here the disease does not necessarily cause disease symptoms at relapse – it often does not - which is why watchful waiting is another standard way to manage the disease. So I anticipate that a purposeful QoL PRO assessment would have to include broad domains such as levels of fatigue, pain, anxiety. I appreciate that such study might require prohibitory large study size and therefore the findings could not be a primary study question unless very large. As secondary endpoints, however, there may be signals sufficient to guide regulatory decisions – such as is the gain in duration of response sufficient (as a surrogate not proven to extend survival) to grant accelerated or full approval? (eg. modest PFS gain, with signals of impairment of QoL for the 1 or 2 year course of treatment) The findings would also guide clinical decisions in usual care should it win approval.
PS I love the design of this platform!!
1 Like
Categorization hurts instead of helps.
I believe Karl refers to categorizing the aims to be achieved by PROs in trials (or the characteristics of patients’ experiences targeted), not categorizing the measures themselves. For example, Karl contrasts organ-specific symptoms of some cancers as against the more diffuse symptomatology that might characterize the experience of (e.g.) an indolent lymphoma.
2 Likes