https://www.nejm.org/doi/full/10.1056/NEJMoa2001282
The abstract:
Methods
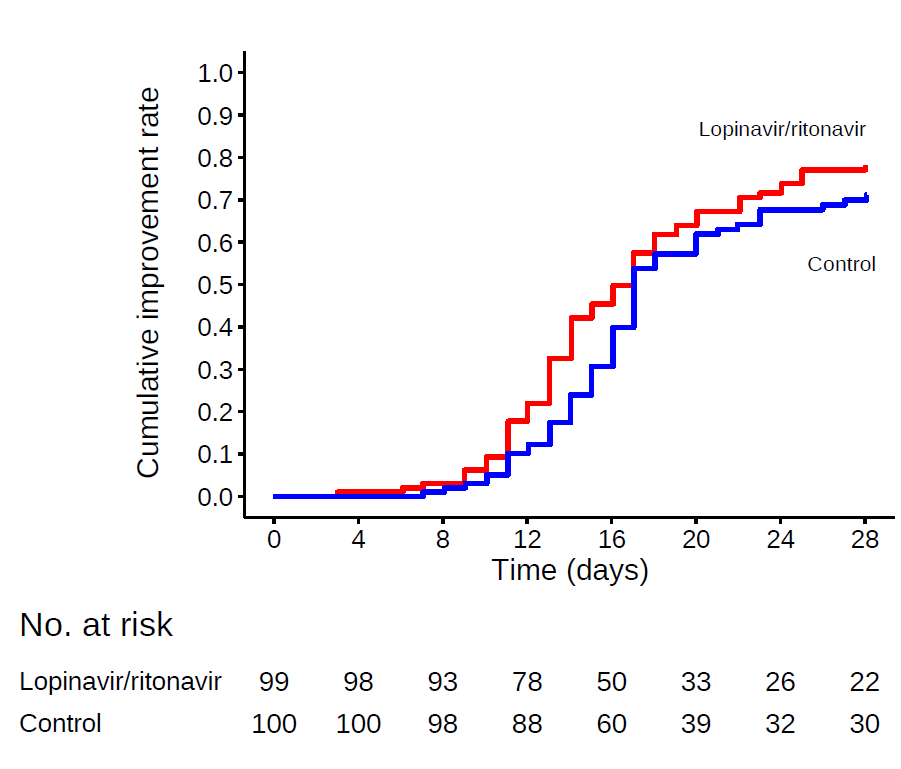
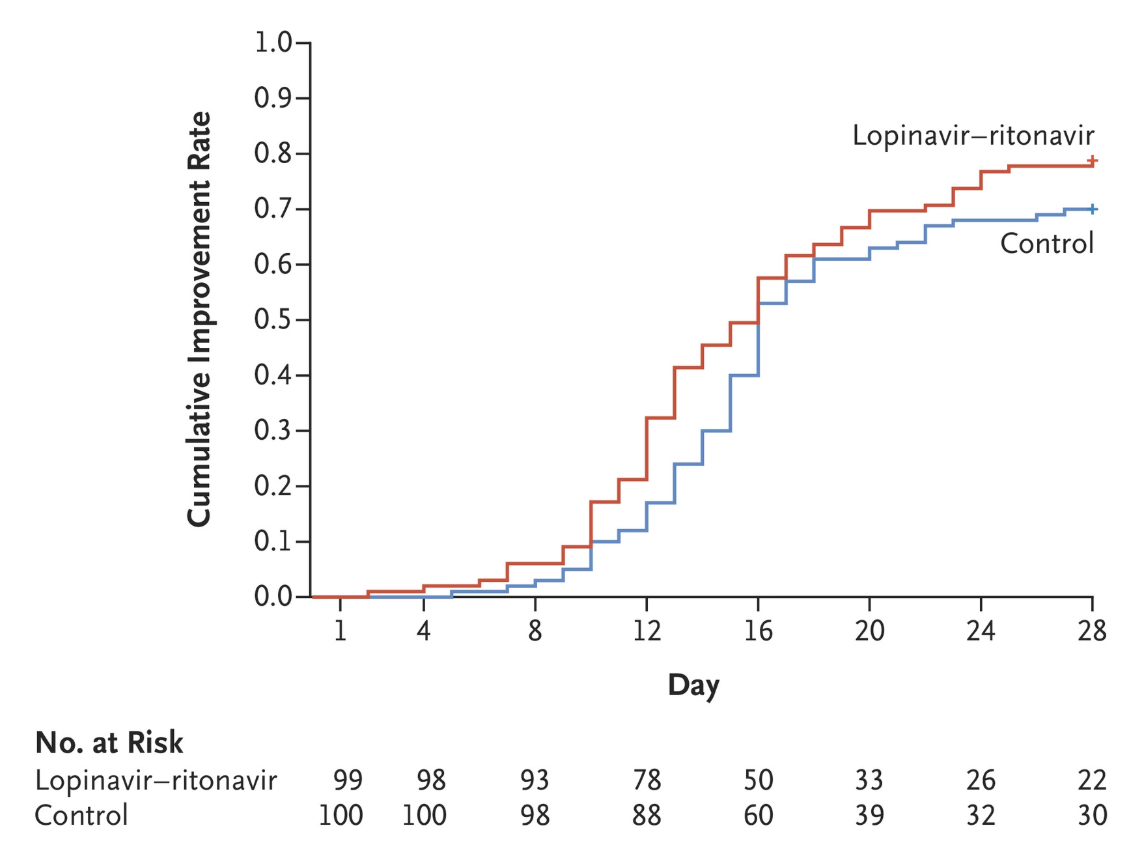
We conducted a randomized, controlled, open-label trial involving hospitalized adult patients with confirmed SARS-CoV-2 infection, which causes the respiratory illness Covid-19, and an oxygen saturation (Sao2) of 94% or less while they were breathing ambient air or a ratio of the partial pressure of oxygen (Pao2) to the fraction of inspired oxygen (Fio2) of less than 300 mm Hg. Patients were randomly assigned in a 1:1 ratio to receive either lopinavir–ritonavir (400 mg and 100 mg, respectively) twice a day for 14 days, in addition to standard care, or standard care alone. The primary end point was the time to clinical improvement, defined as the time from randomization to either an improvement of two points on a seven-category ordinal scale or discharge from the hospital, whichever came first.
Results
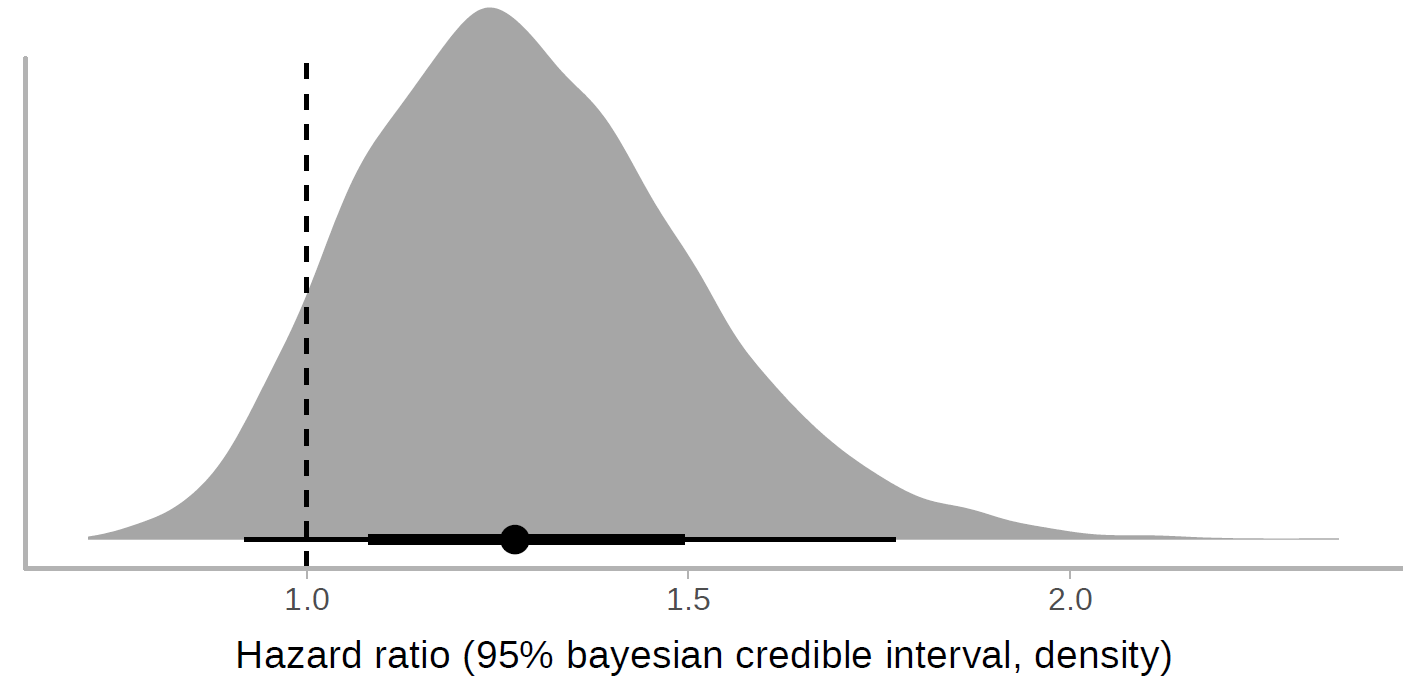
A total of 199 patients with laboratory-confirmed SARS-CoV-2 infection underwent randomization; 99 were assigned to the lopinavir–ritonavir group, and 100 to the standard-care group. Treatment with lopinavir–ritonavir was not associated with a difference from standard care in the time to clinical improvement (hazard ratio for clinical improvement, 1.24; 95% confidence interval [CI], 0.90 to 1.72). Mortality at 28 days was similar in the lopinavir–ritonavir group and the standard-care group (19.2% vs. 25.0%; difference, −5.8 percentage points; 95% CI, −17.3 to 5.7). The percentages of patients with detectable viral RNA at various time points were similar. In a modified intention-to-treat analysis, lopinavir–ritonavir led to a median time to clinical improvement that was shorter by 1 day than that observed with standard care (hazard ratio, 1.39; 95% CI, 1.00 to 1.91). Gastrointestinal adverse events were more common in the lopinavir–ritonavir group, but serious adverse events were more common in the standard-care group. Lopinavir–ritonavir treatment was stopped early in 13 patients (13.8%) because of adverse events.
Conclusions
In hospitalized adult patients with severe Covid-19, no benefit was observed with lopinavir–ritonavir treatment beyond standard care. Future trials in patients with severe illness may help to confirm or exclude the possibility of a treatment benefit. (Funded by Major Projects of National Science and Technology on New Drug Creation and Development and others; Chinese Clinical Trial Register number, ChiCTR2000029308. opens in new tab.)
First, I greatly admire everybody doing trials in this difficult situation and am very grateful to the study authors, I imagine running the study was not easy. My goal is however to help clinicians understand what to take from the study and I believe that the wording of the conclusions could have been better.
For almost all of the reported outcomes (Table 3), the value observed in treatment group was better than in control and the confidence intervals span from some deterioration (e.g., +6 percentage points mortality rate, 0.95 hazard ratio for clinical improvement ) to quite big improvements (e.g. -17 percentage points mortality rate, 1.85 hazard ratio for clinical improvement). I would therefore summarise the results as:
“For severe Covid-19 patients, the study observed a small benefit in using Lopinavir–Ritonavir, but neither some deterioration nor relatively large improvement can be ruled out. We can with some confidence rule out that the drug results in large harm and that the drug is highly effective against SARS-CoV2”.
Further considerations: the study was open label, there were some side-effects of the medication.
The strongest argument against the clinical usefulness of Lopinavir–Ritonavir is IMHO that throughout the study, the treatment group has only very slightly smaller viral loads than the control group (Figure 3), despite already starting with lower viral load at baseline. Not sure how seriously to take this though.
How would you phrase your summary of the study to practitioners? Any other important considerations about the study?
Thanks for any input!