Hypotension prediction index (HPI) is a prediction model (logistic regression) that uses features derived from continuous arterial blood pressure measurements (every 20 sec) to predict hypotension.
The model gives a number (HPI) from 0 to 100 indicating increasing risk of imminent hypotension. By default, an alarm is given when HPI is >= 85.
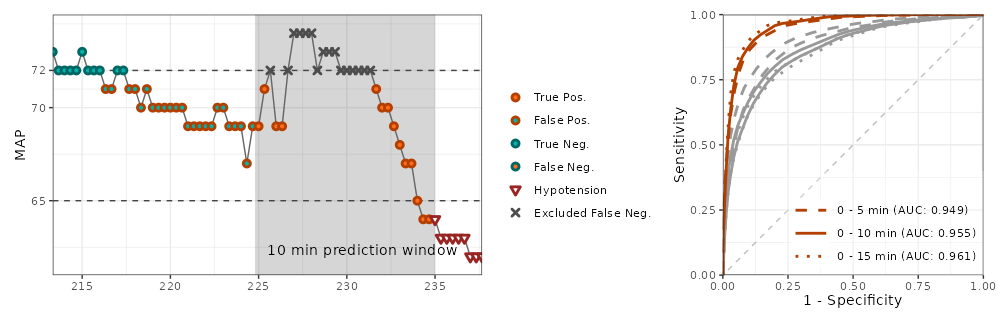
Say we have a time series with HPI values every 20 sec, and a parallel time series marking each hypotensive event. What would be an appropriate way to quantify HPI’s ability to predict hypotension?
The window of clinically relevant prediction is not well-established, but most would agree that hypotension > 15 min after the prediction is irrelevant.
I think the predictions should be approx. 2-10 minutes before the event (if they are less than 2 min before, it is probably too late to intervene).
Precision and Recall
The best I’ve come up with is to use precision and recall, i.e.:
When HPI gives an alarm, how often does hypotension actually occur, e.g., 2 to 10 min later (i.e., positive predictive value or precision); and when hypotension occurs, was there an HPI alarm 2 to 10 min earlier (i.e., sensitivity or recall)? If the alarm is less than 2 min before the event, it is excluded from analysis.
However, precision and recall has the problem, that it is dependent on the prevalence of hypotension.
ROC analysis
Another that has been used, and seems reasonable to me, is to define a target vector which is FALSE everywhere except for e.g. 2-10 minutes before every event, where it is TRUE. Less than 2 minutes before events and during hypotension is excluded from the target vector. A ROC analysis is performed to show HPI’s ability to classify the target vector.
The model actually does not work, but it has been difficult to convince other researchers
Numerous validation studies have been conduced with different approaches. Most are sponsored by the company selling the model, and the results bear mark of this.
The prediction model actually does not work, due to a selection problem that I have described here earlier: A major selection bias affects a widely used model for predicting hypotension