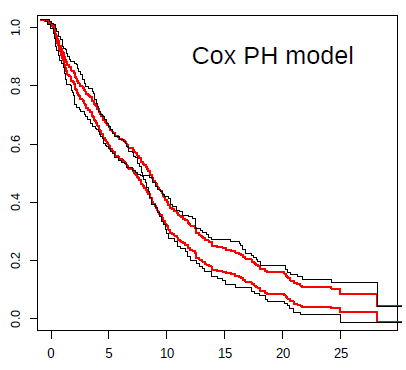
For example, in the case of the Keynote-061 trial, I show a plot with the prediction from the Cox model (in red) against Kaplan-Meier estimates (black). The inability to capture the real effect of immunotherapy in this scenario is very striking. The reason for bias and reduction in statistical power can be clearly seen in this plot. Not being taught this, the next clinical trial in an almost similar population, with the same strategy, repeated the same statistical plan. Both trials were declared negative, despite the fact that immunotherapy possibly offers great benefit to some patients with gastric cancer.