In my opinion, immunotherapy has meant a spectacular improvement in OS in many tumors (melanoma , lung cancer…). So who cares about a technicality when all patients used to die and now there is a large subgroup that survives in the long term? Trials were declared positive with or without the PH assumption. However, as has been common in other areas of science, the great effects have been the first to be revealed, but this will be seen less and less frequently in future trials. Now we have to work finer because there are indications in which immunotherapy may have clinically significant benefit, even if it is not gigantic. These situations will be very important for a smaller but still substantial percentage of patients. For this reason, it is necessary that very fine threads are spun from now on. The prescriptions that have worked before, I don’t think they do it anymore. For example, in contrast to the success achieved in lung cancer, melanoma, etc., the clinical development of immunotherapy in gastric cancer is not going well, although it is clear that some subtypes are very immunogenic, possibly as much as lung cancer. The reason why it is not going well is complex, and possibly has to do with the lack of good biomarkers, but also with the inability to detect modest but substantial effects in a non-PH situation. What is a substantial effect? For ESMO, a 10-15% increase in three-year survival would be a high benefit. I doubt that with Cox regression, we can detect these differences in all cases, despite being considered important by clinicians, in tumors such as gastric cancer.
It was seeminly removed from CRAN and seems to produce errors… ¿?
I don’t believe in Bayes factors as measures of evidence, and it’s hard to apply them other than for a one-dimensional parameter. Instead, you can calculate Bayesian posterior probabilities from a two-treatment-parameter proportional hazards model:
- P(the two survival curves differ at any time t)
- P(the hazard functions differ at a specify time t)
- P(treatment effect is accelerating over time)
- P(treatment effect changes directions over time)
Hello eveyone, as pointed out in the feed, this PH deviation topic is a hot one, especially with the kind of curves seen in IO agents (but not only!). Here’s a paper on this matter published last week.
Deviation from the Proportional Hazards Assumption in Randomized Phase 3 Clinical Trials in Oncology: Prevalence, Associated Factors and Implications
http://clincancerres.aacrjournals.org/content/early/2019/07/25/1078-0432.CCR-18-3999
It reviewed 300 onco phase 3 trials from main journals and found roughtly 25% of deviations from PH (DPH), by detecting non-zero slope on Schoenfeld residuals. The authors reversed the KM plots of both OS and non-OS endpoints and studied other potential covariates. They also tested several alternative methods including the one mentioned ealier, the milestone methods, but also the Fleming-Harrington (FH) tests, the truncated Cox, the RMST, the early/mid/late-weighted log rank tests vs the original (unweighted) LRT. It mentions also some advanced methods but there is no discussion on this topic.
From my side and understanding, back to the Imvigor plot, I wouldn’t say that this is a positive trial either by itself, but more than it deserves more work to identify the tail patients who benefited, and then run a new trial and test the hypothesis again.
Thanks Pavlos_Msaouel for the insights. By the way I think that confidence intervals should always be present on KM plots, at least to appreciate how it widens with censoring.
Hoping this paper helps fueling the discussion 
This is an outstanding paper, thank you for the heads up! One limitation is that they used as a comparator the log-rank test based on what I assume to be marginal survival estimates (this being Kaplan-Meier curves). In practice the log-rank test should almost never be used, whether the PH assumption holds or not. A covariate-adjusted PH model is essentially always preferable and, in such models, the PH more likely to hold than the marginal model.
@f2harrell, I would appreciate your insight on this question that’s been bugging me: from a null-hypothesis significance testing standpoint the PH assumption is satisfied by the fact that the two treatments are identical. If the data are incompatible with the null hypothesis (low p-value), and the PH assumption is clearly violated when looking at the data, I find it hard to interpret this p-value: is it only suggesting (indirectly of course) a difference between the two groups or also incompatibility with the PH model?
Great question. There are two issues as I see it. First there is the always-present problem with what p-values really mean. They provide evidence against a model, and can be small because of either a departure from the null or a departure from the assumed model (here, PH). Second, the satisfaction of the PH assumption under the null (hazard ratio = 1) tells us nothing about the power. It’s the power under the non-null that can suffer when PH is not satisfied.
I have read that there is a joint FDA/industry working group to clarify or get to consensus in this issue. Does anyone know if they have published anything?
i dount that there’d be regulatory guidance for a particular stat method because methods move in and out of fashion and are developed too rapidly for advice to be reasonably static.
Very roughly id say in industry it’s explored in sensitivity analyses (they know the drug and disease and thus what to expect); and in academia non-proportional hazards is considered an interesting result in itself, and not something to lament, just allow for it in the model and report it in the results
edit, maybe this is the guidance you were alluding to, in relation to the iche9 addendum re estimands (not sure it’s been published yet): “We hope that this will provide a contribution to developing a common framework based on the fi-nal version of the addendum that can be applied to design, protocols, statisticalanalysis plans, and clinical study reports in the future”: Treatment Effect Quantification for Time-to-eventEndpoints – Estimands, Analysis Strategies, andbeyond
some relevant remarks from that paper:
“Making testing and estimation consistent even under NPH would methodologically be possible, using e.g. one of the estimators discussed in Section 4 [see refs below]. The tradeoff would be a major logistical and educational effort for all parties involved, i.e. rewriting of programming and reporting templates and education of statisticians, clinicians, HAs, and the broader scientific community on the application and interpretation of these methods. Also, if, as an example, the average regression effect approach by Xu and O’Quigley would be adopted, methodology would first have to be developed e.g. for sample size computation, sequential monitoring of a trial, estimation of this average effect from interval censored data, etc.”
A. P. Boyd, J. M. Kittelson, and D. L. Gillen, “Estimation of treatment effect under non-proportional hazards and conditionally independent censoring,” Stat Med,
vol. 31, pp. 3504–3515, Dec 2012.
R. Xu and J. O’Quigley, “Estimating average regression effect under nonproportional hazards,” Biostatistics, vol. 1, pp. 423–439, Dec 2000
I’d rather have a more flexible model that fits the data than to estimate an average treatment effect. And if Bayesian trial monitoring is used, no new methods would need to be developed for monitoring “boundaries”.
Frank - is “mean restricted lifetime” similar to “Restricted mean survival time” over a certain time period?
Could you expand on this ? i.e, pitfalls of RMST
Restricted mean survival times are defined as the area under the survival curve from baseline to time t. This is a popular method for non-proportional hazards. However, given its definition, one drawback is the crossing curves. As there are portions of the area above and below one of the curves, the method does not seem useful in these cases.
@f2harrell The Royston-Parmar model is implemented in the flexsurv and rstpm2 packages in R. I think it is a nice and useful model to describe the evolution of hazards and OS in complex scenarios. What do you think?
@PaulBrownPhD Through this thread, one of the things I have been able to grasp is that non-proportional hazards is a phenomenon that is not really unique, but a tailor’s drawer, with recipes and methods that may not be equally useful for all patterns. Therefore, the researcher has to know his field well, and ‘bet’ on the most appropriate method, for the expected data. Right?
I think this model as well as predecessors by Herndon, Shin, and myself are very useful in this setting. They solve some computational problems while allowing sufficient flexibility. The key challenge is translating time-specific hazard ratios to clinical efficacy.
It is instructive to see how the things that now interest ‘new’ oncologists are the same or parallel topics that some data analysis pioneers were passionate about in the past. Are some of those flexible models available in any R packages? I’d like to try.
it does feel like a gamble, but much of drug development already feels like a gamble. It’s also deliberately counter to the anti-parsimony principle i’ve heard Frank Harrell and Gelman refer to: Against parsimony, again. I think doing a simple and conventional analysis is (cutting-and-pasting), rightly or wrongly, is thought to minimise the gamble
@Pavlos_Msaouel Pavlos, the reason why the confidence intervals do not increase is because the estimate takes into account all patients who failed before time point t, as well as all patients with some observation, who were censored before t. If only the available data to the right of the curve were used, ignoring the rest, effectively the confidence interval would be greater. Graphs with time-dependent hazard ratios, on the other hand, do increase the amplitude of the confidence interval, to the right.
This is not relevant to this topic. Please delete this post and re-post it to an appropriate new topic on the site.
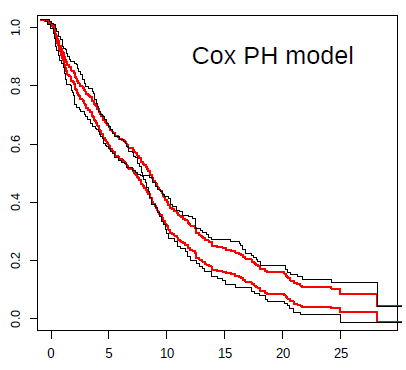
As a follow-up note, we finally published an article gathering some of the ideas in this Datamethods thread. We basically digitized 6 immunotherapy trials with crossing hazards and saw that the Cox model and the log-rank test worked really badly here. This is already known by you, but we thought it was necessary to exemplify it. For example, I found it very curious that a phase III in gastric cancer was declared negative (Keynote-061), and then another similar study was designed (Keynote-062), for the same strategy, with the same statistical plan aimed at not capturing the dynamic effect of immunotherapy. Therefore, they stumbled upon the same stone twice. This trial has been extensively discussed in oncology forums, and its convoluted hierarchical design has been criticized, but as far as I know, no one has commented on the problem of crossing survival curves. Therefore, we felt it was necessary to share this with clinicians. Thank you to all of you who have helped me.
For example, in the case of the Keynote-061 trial, I show a plot with the prediction from the Cox model (in red) against Kaplan-Meier estimates (black). The inability to capture the real effect of immunotherapy in this scenario is very striking. The reason for bias and reduction in statistical power can be clearly seen in this plot. Not being taught this, the next clinical trial in an almost similar population, with the same strategy, repeated the same statistical plan. Both trials were declared negative, despite the fact that immunotherapy possibly offers great benefit to some patients with gastric cancer.