I have for some time been pessimistic about the yield to patients and to public health of the incredible amount of funding that has been put into high-dimensional data, electronic health record research, precision medicine, and so-called heterogeneity of treatment effect. I would like to offer some current assessments in the hope that others will discuss these areas in more detail and provide references for review articles.
Some practitioners of machine learning (ML) have analyzed data in such an aggressive way (especially when the number of candidate features exceeds the number of patients) that they overvalue the true information content in the data. Most of the currently used analytic techniques have zero probability of finding the right data features for predicting prognosis or for diagnosis. Attention to FDR (false discovery rates) to the total exclusion of false negative rates and lack of appreciation for how feature selection distorts inference have a lot to do with this. As with statistical models, machine learning cannot find information in data that is not there.
Precision medicine has led more to precision capitalism than it has benefited public health. And one seldom sees evidence that a complex molecular signature provides useful information over and above clinical variables and standard blood analysis.
Especially in the area of prognostic models, real world data such as data from electronic health records are being analyzed without a full appreciation for measurement errors, missing data, or the definition of time zero. When isolating treatment effects is a goal, confounding is often poorly addressed.
Big data can be a curse because the dataset may be too large to quality control or to even understand all the variables. Many ML applications have been published in medical journals where the analysis did not even distinguish independent variables from dependent variables. I would rather have a 1,000 patient dataset prospectively collected and quality controlled than a 100,000 patient “real world” dataset.
The majority of ML applications in medicine are still using classification methods rather than risk prediction. It is time for researchers to realize that classification provides limited information, is arbitrary, is more prone to patient sampling issues, and is at odds with medical decision making.
It is not enough to demonstrate that a predictive algorithm has good predictive discrimination. When a prediction tool is to be used in decision making it is imperative that a rigorous calibration validation be undertaken to demonstrate good absolute predictive accuracy. The calibration assessment should use a flexible calibration curve estimator. The majority of publications involving ML in medicine still do not contain a valid calibration estimate.
Model and ML performance in risk prediction seldom quantifies predictive information in clinical terms. More use needs to be made of simple yet versatile measures that are clinically founded, such as the proportion of patients with risk predictions < 0.1 or > 0.9, or better, a 100-bin histogram showing the entire distribution of predicted risks. The utility of a biomarker can be demonstrated by how much the addition of the biomarker to the model shifts the risk distribution to the tails.
Dear prof,
Is it necessary to tackle confounding in prediction models? My concept was it is important only in explanatory models , not in prediction unless something like causal prediction. Please discuss
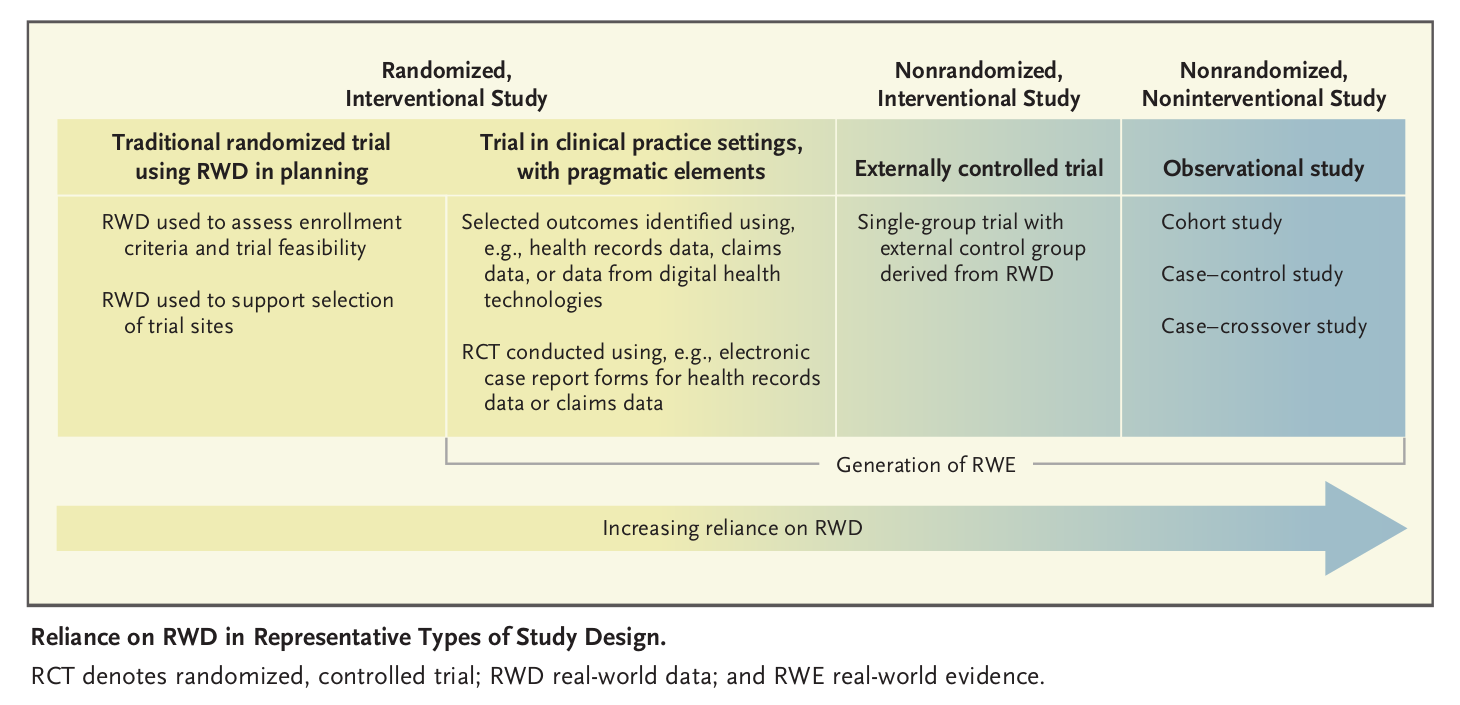
regarding ‘real world data’, the figure below from nejm perspective suggests there’s an increasing reliance on RWD but this appearance may be caused by rebranding things as RWD. Eg, there is nothing new about using historical controls, nor is there an increasing reliance on such designs
it remains to be seen exactly how RWD would be used in a new way to supplement RCT data for approval of a drug product. Is there is an interesting example in the literature that is not just hype? The EMA has plans: Data Analysis and Real World Interrogation Network (DARWIN EU) | European Medicines Agency But we don’t know how exactly such data would be integrated with RCT data in a novel way that alleviates concerns re data quality. It seems likely that RWD will merely inform the design of the RCT in some way, but this is nothing new
I wholeheartedly agree re the value of prospectively collected and controlled data. And this goes for safety studies too. The EMA recently sought a real world data expert (whatever that is) and the job description said the person must advocate for RWD, rather than eg ‘evaluate the potential value of RWD’. It’s essentially marketing then that the statistician may find himself/herself up agaisnt, we need to reclaim the discussion, as you’re doing. Regarding ML, we need to advocate for high quality clinical trials as this review concludes: Clinical impact and quality of randomized controlled trials involving interventions evaluating artificial intelligence prediction tools: a systematic review
i worry about the naivety of statements like this: “We have long known that many populations are underrepresented in RCTs and that it is unrealistic to expect head-to-head trials for every intervention and combination, in every patient subgroup of interest, and in situations that closely mimic routine care. Calling this situation a gap sounds more like a crack in the sidewalk than the chasm described here. Why not guide decision making with both RCTs and real-world evidence? The guidance might be imperfect, but nonetheless preferable to assuming that all patients will benefit equally, regardless of vulnerability. If we treat RCTs and real-world evidence as complementary, it will strengthen evidence-based medicine for all patients” (from: Strengthening evidence-based medicine with real-world evidence) RWD can generate ambiguity, disagreements about interpretation etc, which does not assist the definitive RCT
Excellent point. Confounding comes into play if you are trying to isolate a treatment effect in the analysis.
Excellent points Paul and thanks also for the table. Yes we’re seeing a lot of hype around RWD. In many cases RWD are not even needed to apply RCT results to the full clinical population (e.g., when the RCT enrolled people with wide covariate distributions). The kind of RWD that in my view will be most valuable will come from intentional and sometimes expensive personal monitoring (of physical activity and physiologic activity) as outome variables as to better dose medications.
The kind of RWD that in my view will be most valuable will come from intentional and sometimes expensive personal monitoring (of physical activity and physiologic activity) as outcome variables as to better dose medications.
Confounding should ideally be accounted for whenever possible in prediction models. We provide here an example (Figures 6C and 6D) of confounding that should be modeled when transporting knowledge from a prediction model. The need to account for underlying causal relationships, such as confounding, is also recognized in healthcare AI applications and in clinical risk prediction modeling. Additional arguments and counterarguments here and here. There is also interesting recent work on conditions that could allow partial specification of confounding relationships.
Examples: objective physical activity data collected continuously to augment what occasional 6 minute walk tests tell us; continuous monitoring of cigarette smoking.
From a medical standpoint, I’m pretty skeptical of the potential value of most types of physiologic monitoring, beyond what is already available.
I can see how monitoring could be quite valuable in certain research areas (e.g., objective measurement of physical activity level like #steps/day in those being treated for progressive/chronic neurologic conditions or in rehabilitation science), but activity level can be measured fairly easily/inexpensively/non-invasively. Maybe some type of outpatient monitoring in patients with certain types of epilepsy could also prove useful?
It would be great if we could somehow monitor BP continuously in patients over the long course of antihypertensive clinical trials, to better characterize the relationship between BP and CV outcomes. But unless we can then afford to outfit every hypertensive patient in daily practice with some type of continuous BP monitor after the RCT is done (so as to better characterize his own BP response to treatment), the value of that more granular RCT knowledge will be limited.
We can detect atrial fibrillation with a watch, but, to the best of my knowledge, we really have very limited understanding of when the risk/benefit ratio for anticoagulation becomes favourable for a given patient as a function of overall a.fib burden. The patients enrolled in the old anticoagulation trials for a.fib did not have their a.fib diagnosed based on a 2 minute run of a.fib detected on a watch…
Continuous glucose monitoring has been liberating for many patients with diabetes who are treated with insulin. The ability to promptly identify, and therefore treat, hypoglycaemia, and to adjust insulin doses accordingly, has been a life-changing medical advance for many patients.
Aside from the above examples in specific disease areas, though, my impression is that most of those who extol the “untapped potential” of other types of physiologic monitoring are divorced from the realities of medical diagnosis/practice and the needs of patients and are motivated by greed rather than altruism. There’s a lot of money to be made by convincing the affluent “worried well” that there’s inherent value in obsessive monitoring of every bodily function, but precious little evidence that such monitoring changes outcomes.
The crucial element of such monitoring is, I think, whether it gets folded into control loops or whether it merely “captures” information for the extractive industry of what you nicely termed “precision capitalism.”
There’s certainly a place for retrospective, higher-order learning about the control algorithms themselves. But I posit that any purely extractive “capturing” of information solely to support promised inference in the future isn’t sincerely motivated by patients’ needs.
Thinking “head-to-toe” of all drug classes in common use, there are actually very few for which drug dose would plausibly be adjusted based on some type of physiologic monitoring, either for efficacy or safety reasons. For symptomatic conditions, we usually dose based on symptomatic improvement (e.g., inhalers for asthma, analgesics for nerve pain, beta blockers for angina); toxicity is gauged not by blood level, but by reported dose-limiting side effects or office findings (e.g., sedation with gabapentinoids; bradycardia with beta blockers). These dosing decisions would not likely be meaningfully enhanced by more detailed physiologic monitoring. For asymptomatic conditions (e.g., asymptomatic CAD), we tailor dose to level of risk, often in combination with periodic blood testing to guide dose adjustment (e.g., aiming for substantial decrease in LDL)- decisions to stop a statin are largely clinical, not lab-based.
In addition to ambulatory BP monitoring and blood glucose monitoring for patients on insulin, home INR monitoring for patients on warfarin who have labile INRs, or antiepileptic drug level monitoring for patients with very brittle epilepsy (who also quickly develop side effects at supra-therapeutic drug levels), are the only examples I could think of for which more frequent physiologic monitoring plausibly could be helpful.
One thing that frustrates (well…one of the many things that frustrates) is how “generalizability” is used as a cudgel to diminish trials and promote so called RWD. However, just as nobody steps into the same river twice, there is no assurance that your prediction/effect-estimate calculated from RWD is similarly useful outside the specific context it was developed in. Yet there is seemingly zero attention paid to the possibility of changing/different distributions of major drivers of risk or effect modifiers, while the first thing any trial gets called out for is how its effect estimates can’t possibility be transportable, even though trialists seem to talk about this challenge much much more than he RWD set.
Extremely well said Darren. This reminds me of my belief that what RWD excels at is describing prevailing outcomes of prevailing treatment strategies. Not much more than that (other than doing a good job of describing who gets which treatment) and not causal.
I share your pessimism @f2harrell about the ability of high-dimensional data, electronic health record research, precision medicine, and so-called heterogeneity of treatment effect to provide useful clinical information. Traditionally, clinicians like me use diagnostic tests on their own to do this but admittedly with limited success. Simplistically, a test results within the normal range predicts that there is a low probability of an adverse disease outcome without treatment and it remains much the same if treatment is given. However, if it is outside the normal range, it is assumed that there will be a difference between the probability of the outcome on treatment and no treatment. However, the probabilities of an outcome on treatment and no treatment changes with the ‘severity’ of the test result and not in a ‘cliff edge’ within and outside the normal range.
It should be possible with care to take covariates into consideration possibly to increase the differences between the probabilities of an outcome with and without treatment. For example, if the albumin excretion rate (AER) is low (e.g. 20mcg/min) then it suggests that there is little renal glomerular damage and therefore little scope for improvement by treatment with an angiotensin receptor blocker (ARB). The probability of developing ‘nephropathy’ within 2 years is therefore about the same on control (e.g. 0.02) and treatment (e.g. 0.01) in figure 5 of a previous post: Should one derive risk difference from the odds ratio? - #340 by HuwLlewelyn . However, at an AER of 100mcg/min, the probability of nephropathy on control is 0.24 and on treatment it is 0.1, a risk difference of 0.14. In the RCT the covariates HbA1c and BP were kept to a minimum by treatment before randomisation so that the baseline risk was very low in the RCT. However, if there was poor diabetic control in an individual as evidenced by a high HbA1c, then this high risk should not be improved by treatment with an ARB as the latter does not improve diabetic control so that the risk reduction at an AER of 100mcg/min, would remain about 0.14. Another source of ‘heterogeneity of treatment effect’ would be the drug dosage of course, the expected difference being zero at a drug dosage of 0mg per day, increasing as the drug dosage is increased.
The above reasoning represents a hypothesis based on the results of a RCT. I agree therefore that it has to be tested by setting up calibration curves. I would be optimistic that a model based on the above type of reasoning based on a RCT result would provide helpful clinical predictions, unlike more speculative approaches.
Huw - this is the kind of reasoning that should take place much more frequently than the “wing and a prayer” high-dimensional analysis that seems to get most of the research funding. Thanks for your thoughtful post, as always. And there is a lot of unharvested information in clinical lab data.
I have read the above paper. It does not seem to say so explicitly, but is it possible to use the fitted loess curves to arrive at a function that ‘calibrates’ the model’s estimated probabilities so that when each of a very large number of the ‘calibrated probabilities’ are plotted against the frequency of correct predictions, they should provide a line of identity?
These look like interesting papers, and I’ve only just glanced at Figures 6C and 6D, so apologies if there is an obvious misconception on my part.
I would not call the problem you cite in those figures confounding. If you were interested in the causal effect of prognostic variables on the outcome, perhaps. But we’re not. Rather, we’re interested in applying the whole predictive function to external populations. (That causal effects of the outcome may make the best predictors—while I agree—is somewhat beside the point.) Geographic area or baseline risk, as illustrated, would be potential modifiers of the effect of treatment on Y, which is why they must be accounted for when transporting predictions from one population to another.
Does that make sense? Perhaps once I read the papers I’ll have a better feel for this language in the context of prediction. Thanks for sharing.
No prob. Note however that the argument here becomes circular whereby you would only call a variable a confounder if you were interested in what you would define as causal inference. However, regardless of the definition used, the assumed causal relationship shown in these figures is of the type: X ← C → Y where X is the prognostic variables and Y is the outcome. We typically call C here a “confounder”.
Even if we do decide to call “C” something else, that does not change the fact that it is the presumed commonalities in causal mechanisms that license the transportation of knowledge across populations. Thus, we cannot avoid the use of causal considerations no matter how hard we try. They lie at the foundations of statistical science, including when predictive models are being developed.