Thank you Professor!
Here are the results of my updated analysis.
Please, any comments or suggestions for improving it?
- Chunk test / likelihood ratio chi-square test for added predictive value of the clinical measures altogether:
# Chi-Square d.f. P
# 6.386165e+01 7.000000e+00 2.545708e-11
-
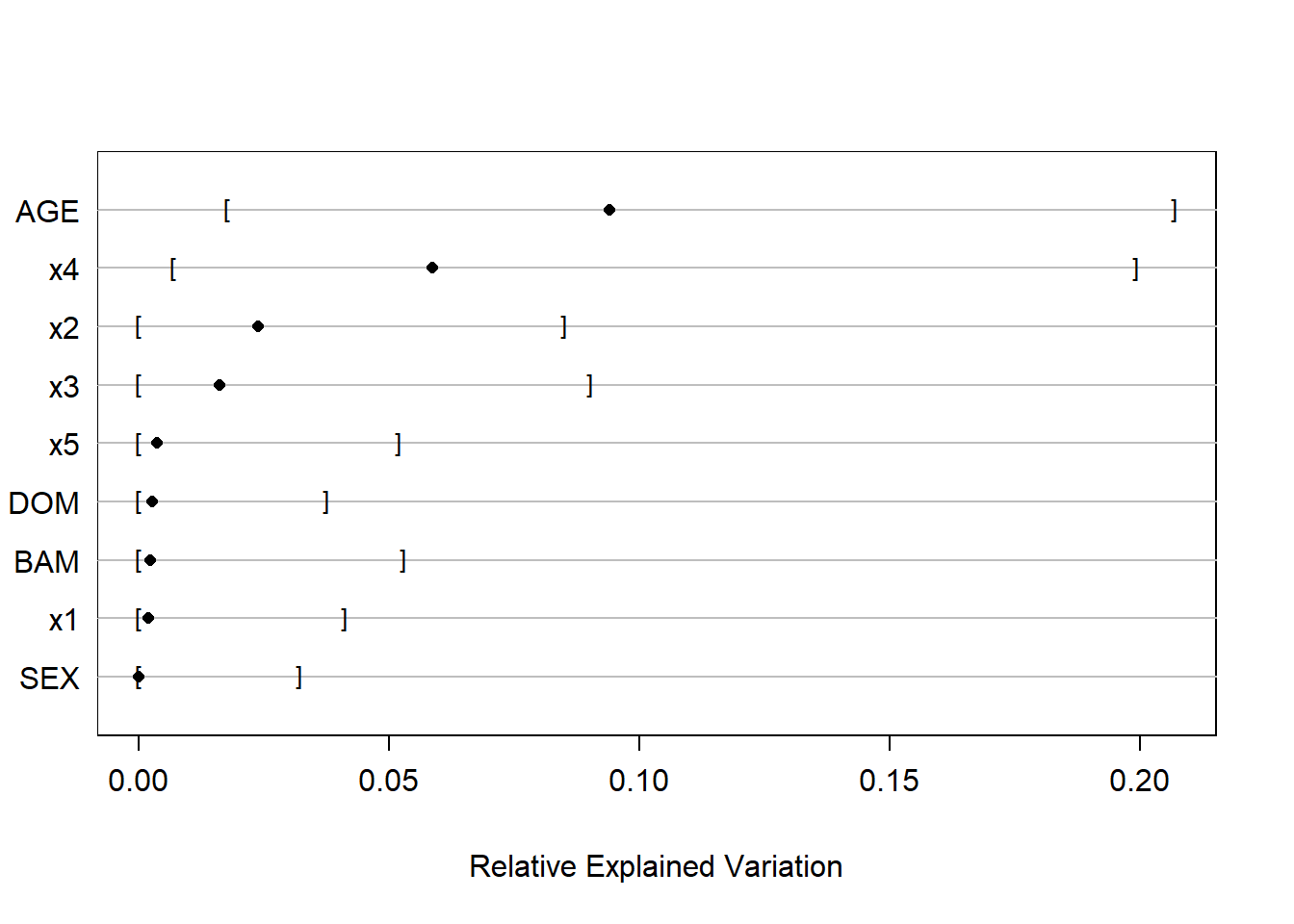
REV (500 bootstrap resamples of the full model):
-
Fit x4 model:
lrm(formula = y ~ DOM + BAM + SEX + rcs(AGE, 3) + rcs(x4, 3),
data = data, x = T, y = T) -
Anova (Likelihood Ratio Statistics):
Significant association of AGE (df=2; p=0.0007) and x4 (df=2; p<0.0001) -
Bootstrap model and partial effects plots:
-
Model validation with bootstrap (B=500):
Somer’s D (corrected index) = 0.5455 -
Model calibration with bootstrap (B=500):
Mean absolute error = 0.014
0.9 Quantile of absolute error = 0.025
-
Nomogram: