Despite being published just over 20 years ago, I think this paper on Bayesian model averaging complements the discussion and recommendations in RMS. It explains the problems with prediction based on single models (and by implication step down methods which select the “best” model using the data) in the introduction.
Their discussion of frequentist solutions in the last section is an apt description of RMS and much has been done from this perspective since that paper was written.
It may have been mentioned in the many RMS references, but I was not able to find it despite looking this morning.
This discusses computational aspects that simplify the implementation of Bayesian Model Averaging.
Excellent papers. In general I favor using a single “super model” that has parameters for the same things that model averaging allows for, with shrinkage priors on the complex effects (e.g., unequal variance, interactions, non-proportional hazards or odds).
I have a general question about calibration that I can’t find a description of here nor in other relevant resources. What are the common sources of miscalibration in predictive modelling? Could you please refer me to the relevant papers?
Start with Ewout Steyerberg’s book Clinical Prediction Models. The number one culprit is overfitting, related to regression to the mean, which causes low predictions to be too low and high predictions to be too high.
I have a new question related to this - is there a way to combine calibration plots over multiple imputations, to get one final “combined” calibration plot?
See the April 24 post above. One approach is to create 40 calibration curves for 40 completed datasets, and to average the 40 curves. Each calibration curve is estimated by resampling on a single completed dataset.
Hello! I have a question about rms package and lrm model. When I run validate (MyModel, bw=TRUE, B=400) I get the report “Frequencies of Numbers of Factors Retained”. How can I sum what exactly factors have been retained during bootstrap procedure? The factors are marked with asterisks, but I cannot count them.
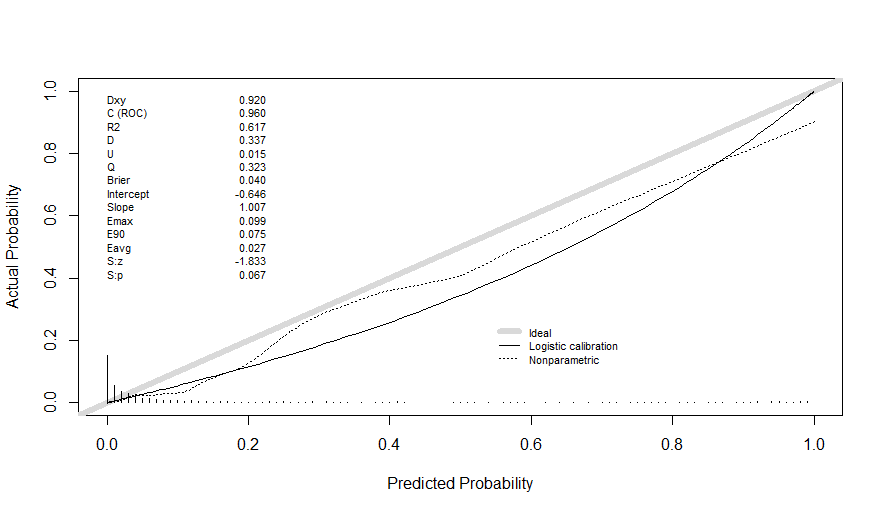
Greetings! Do parameters of the calibration plot (Slope, Dxy and others) belong to a nonparametric calibration curve or to the logistic calibration curve?
Somers’ D_{xy} is independent of calibration. Calibration slope and intercept come from assume a linear (in the logits) calibration curve and fitting it with logistic regression. Indexes starting with E come from the nonparametric curve. There are also integrated calibration measures from the nonparametric curve, in the literature.
Nomogram with one predictor contributing very minimal
We developed a clinical prediction model with prespecified predictors and a full model and with enough effective sample size, with an optimism corrected AUC of .95. In our nomogram, one predictor contributes only minimal points, 2 or 3 points only and the beta is only zero. What to do? We have prespecified the full model. penalization done. I am tempted to remove that variable.
i would like to have your opinion
It is most accurate to keep the weak predictor in the model and in its displayed nomogram. This will not affect the predictions so much but will affect what the nomogram doesn’t show—the precision (e.g., standard error) of estimates. An alternative is model approximation, also known as pre-conditioning. Use the full model as the basis for inference and standard error calculations but display the reduced model. For an example see this.
I have a model for which I have validated using optimism-adjusted bootstrap. However, we are interested in the performance of this model on subsets of the data (e.g. individual treatment arms). The reason for this inquiry is because treatment arm is the model’s strongest predictor and we are interested to know how well the model will perform within a given arm. Is there a way to apply the rms::validate function on selected subsets of the sample used to train the model?
I spoke too soon. The work of resampling validation is done by the rmspredab.resample function which accepts a subset= argument. Give that argument to validate or calibrate and it will be respected.
Thanks.
I just want to make sure I understand what’s happening. When I pass the subset argument to validate, e.g. validate(fit, method = “boot”, subset = data$ARM = “A”), am I fitting the model and performing all resampling necessary for bootstrap with ALL subjects however only assessing the predictions made on subjects in ARM A? Or is this somehow only sampling from the subjects in ARM A (in which case it shouldn’t work if ARM was in the model fit)?