I think we can move on to part 2 based on the discussions thus far. We all have agreed with Sander that it makes sense to use a model form linear in the natural parameter of the data distribution (i.e. logistic for risks) and we also agree that it obeys the logical range restrictions of the outcome, makes the usual large-sample approximations (e.g., Wald P-values and CIs) most accurate in finite samples, and therefore makes the ORs the easiest summary measures to calculate. The logistic model also results in less misspecifications as Frank has repeatedly said, produces more meaningful predictions, has no boundary problems and is variation independent as we all agree on.
The main argument that remains is that it does not preserve collapsibility – i.e. the ‘logical problem’ of the marginal odds ratio not lying in the convex hull of stratum-specific odds ratios – apparently that ‘cannot be right under any circumstances’ and therefore, despite all of the above justifications, the OR cannot be a parameter of interest for causal inference or inference in general. Also there seems little agreement on derivation of collapsible effect measures from logistic modeling.
Preservation of collapsibility is posited to give the following benefits:
a) Align with some imaginary data generating mechanisms
b) Ease interpretation of effects in real life
c) Enable causal inference to proceed for which collapsibility is mandatory
d) Collapsible effect measures need new models to overcome their inherent modeling problems because they cannot be derived from odds ratio modeling
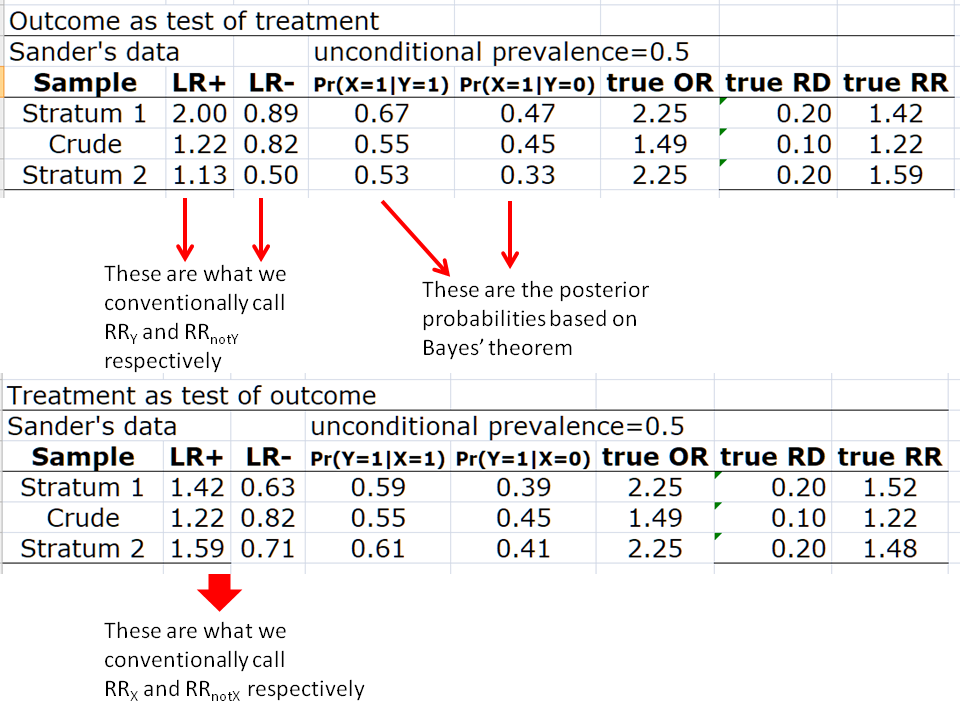
I now move the figures I posted above into a Table below:

The data (in the previous figures and the table above) are from Table 1 in Greenland Pearl and Robins (Statistical Science). From the diagnostic test perspective we now understand what the issue is - the RRs that have been considered collapsible are not really the associational RRs of interest - they are the likelihood ratios derived from our application of Bayes’ theorem (columns 2 & 3 above). Only after we derive posterior probabilities using these likelihood ratios (assuming baseline probability = 0.5) can we define the ‘true’ risk difference or risk ratio of posterior probabilities - and as expected they are also ‘noncollapsible’. Note I am using the outcome as a test of the treatment status for convenience only because the LRs then align with the RR. The same would also apply vice versa given that ORs are symmetrical.
In summary it seems that collapsibility only exists because the LRs are collapsible (as expected) but these LRs were (unfortunately) considered to be effect measures of primary interest