I removed ‘Huw’ from z^\text{Huw}_\text{repl} = z_\text{repl} \frac{\sqrt{v_2}}{\sqrt{v_1+v_2}} as I thought that it was a misrepresentation of my view. Perhaps I should have written z^\text{Erik}_\text{repl} = z_\text{repl} \frac{\sqrt{v_2}}{\sqrt{v_1+v_2}} to make it more explicit, but I thought it would be impolite at first to use your first name without your permission!
The usual definition of the z-statistic is the estimator divided by the standard deviation of its sampling distribution, so that is b_\text{repl}/\sqrt{v_2}. For this reason, I write z_\text{repl} = b_\text{repl}/\sqrt{v_2}.
In your post 217, you suddenly defined the z-statistic of the replication study as b_\text{repl}/\sqrt{v_1+v_2}. Correct? This is an unusual definition because it involves the sampling variance of another study. Since you are using an unusual, personal definition, I write z^\text{Huw}_\text{repl} = b_\text{repl}/\sqrt{v_1+v_2}.
[quote=“EvZ, post:245, topic:7508”]
If you really must, you can write z^\text{Erik}_\text{repl}
You introduced this ‘Huw’ business. I thought that ‘you’ and ‘me’ was a little better but not much. As you have already suggested, we should stick to more descriptive terms.
Therefore Llewelyn’s formula would be in descriptive terms would be:
Note that the difference is that where Llewelyn has 1.96 on the left had side of the equation, van Zwet instead has 1.96.(s/√n2)(NB it uses n2) on the left hand side and Goodman instead has 1.96.(s/√n1).(NB it uses n1) on the left hand side.
It’s written differently to the way you have expressed it in the past (you may regard the new version as ‘wrong’ because of that). People should care because it’s important to understand that van Zwet’s expression does not regard replication as getting ≤pnorm(1.96) = P≤0.05 again but a different P value limit: P≤ pnorm(1.96.(s/√n_2)) again.
The ‘z-statistic’ is the raw value ‘b’ divided by a standard error of {\sqrt{\left( \frac{s}{\sqrt{n_1}} \right)^2 + \left( \frac{s}{\sqrt{n_2}} \right)^2}} which is not weird but using your analogy, secondary school stuff. This expression for the ‘z-statistic’ can be seen in plain sight to take up most of the right hand side of Llewelyn’s expression. To say that it is being hidden from my notation is just being mischievous!
Your b_\text{repl}/\sqrt{v_1+v_2} is not a z-statistic in the usual sense, because it is not an estimator divided by the standard deviation of its sampling distribution. That you call it a z-statistic is therefore misleading. I’m upset by that, but there’s nothing I can do about it.
The event |b_\text{repl}/\sqrt{v_1+v_2}|>1.96 does not have 5% probability under any null hypothesis of interest. In particular, it does not have this property under H_0 : \beta=0. I’m upset that you claim it does, for instance in the abstract of your pre-print:
The occurrence of the event |b_\text{repl}/\sqrt{v_1+v_2}|>1.96 has nothing to do with replication success as it is commonly understood. It is also clear that you couldn’t care less.
I can’t remember stating that b_\text{repl}/\sqrt{v_1+v_2} was a statistic. Perhaps it was a misunderstanding again. I don’t want you to be upset. Would you be happier if I described b/\sqrt{v_1+v_2} as a predictive z-score?
Call it what you want, but just don’t use a term that is already used for something else (like z-statistic or z-score, predictive or otherwise).
Your main challenge is to explain why the occurrence of the event |b_\text{repl}/\sqrt{v_1+v_2}|>1.96 would have anything to do with replication success. I don’t see it.
Furthermore, you should not make claims that are not true, like that |b_\text{repl}/\sqrt{v_1+v_2}|>1.96 corresponds to P \leq 0.05.
If your numerical formulas aren’t to be interpreted as statistics from a mathematical point of view, how are any of us supposed to interpret them according to the rules of probability theory or results in statistics?
AFAIK, your formula has no interpretation as a realization of a random variable from any probability distribution.
So in view of the above, how do you explain the results below? If your theory suggests that something cannot happen but it does happen, what do you do? Don’t you change your theory?
What we are doing of course is trying to derive mathematical models to predict the result of a natural process, which is always difficult (like medical prognosis). When n2 = ∞, then both EvZ and HL expressions give the same probability of replication. For example in your two simplified examples, when n2 = ∞, instead of √2 in the denominators we would get √1 and EvZ and HL expressions give the same result of ɸ(b/1-1.96). A difference happens when n1<<∞ and n2<<∞ and when n1=n2 or when n1≠n2.
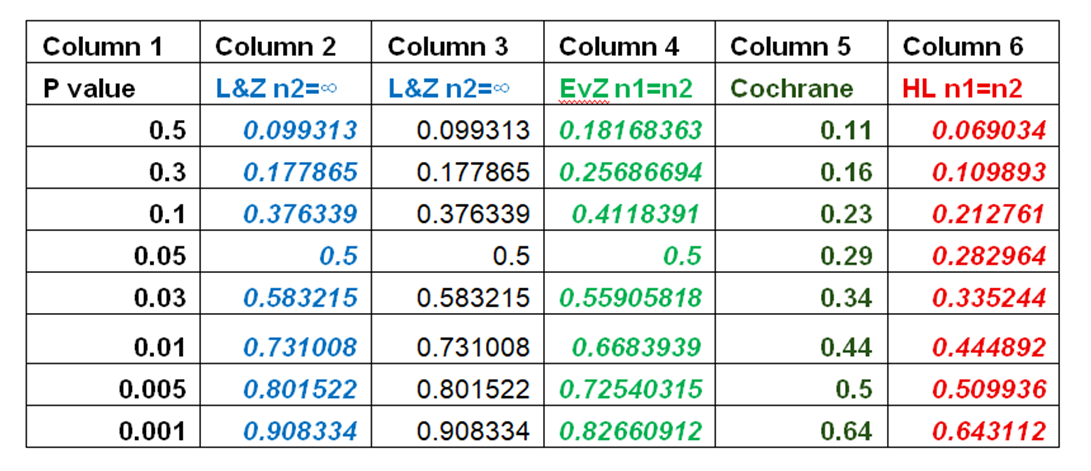
Table 1
Columns 2 to 6 of Table 1 show the probabilities of replication for different P-values from P=0.5 to P=0.001 as laid out in Column 1. The probability of replication for both methods HL and EvZ are in Columns 2 and 3 when n2 = ∞. Column 4 shows the probabilities of replication using the EvZ expression when n1=n2. Column 5 (Cochrane) shows the probabilities of replication arising from the Cochrane data as described in van Zwet, E. W., & Goodman, S. N. (2022) (see (link) in post number 50). Column 6 sets out the probabilities arising from HL’s expression when n1=n2
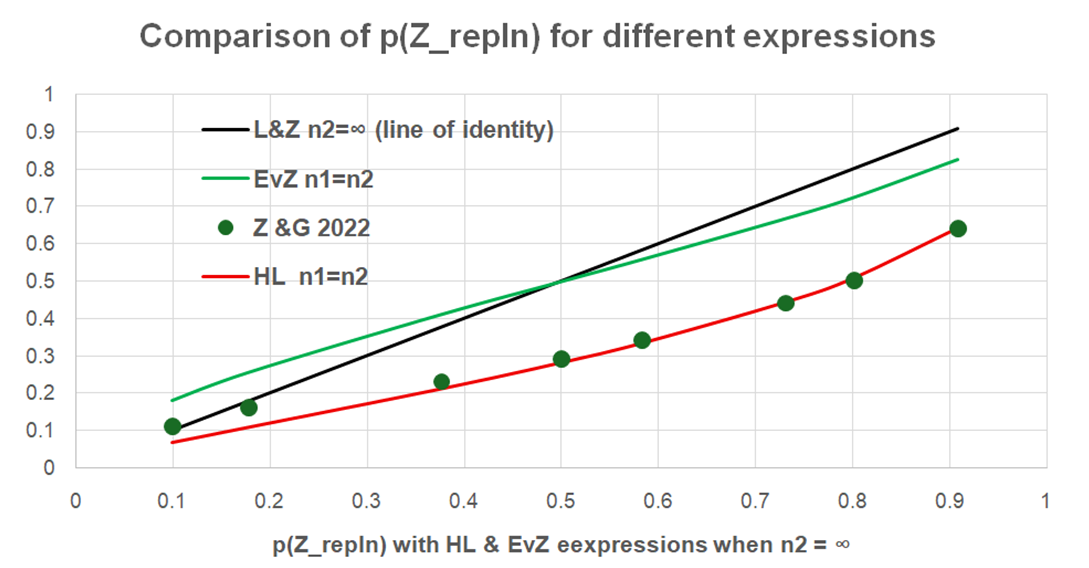
Figure 1 is a plot of the data in Column 2 (on the horizontal axis) against columns 3 to 6. The horizontal scale is the probability of replication for both methods HL and EvZ in Columns 2 and 3 when n2 = ∞. The black line is of identity when the expected probability of replication in a second study conditional on the P value based on n2 = ∞. The large green points are the probabilities of replication conditional on the P value based on the Cochrane data. The red line is the probability of replication conditional on the P value based on HL’s expression; this predicts very well the Cochrane probabilities of replication. The green line represents the probabilities of replication conditional on each P value based on EvZ’s expression. The latter overestimates the Cochrane results and is very close to the line of identity. It also predicts that when P>0.05 and n1=n2<< ∞ , the probability of replication is greater than when N2 = ∞, which does not make sense. Therefore HL’s approximation appears to give plausible predictions of replication whereas that of EvZ does not.
What is you explanation for this? Am I mistaken in any way? If so how?
Goodman and van Zwet fit a probability distribution to empirical data from RCTs to derive a data based prior distribution to aid in the interpretation of medical trial results. There is no objection to their mathematics.
Your “derivation” isn’t based on any mathematics, and has no logical or empirical relationship to their result. It is pure coincidence.
You know that that is unrealistic. What I have done is postulate a reason for the unexplained replication crisis, which is an important medical and other scientific issue. I have expressed my hypothesis mathematically and numerically in order that I could test it. So far the results are compatible with my hypothesis. That is science. I am sorry that it is not to your liking.
If we thought that, then we would still believe that the sun went around the earth or that sickness was caused by the four humours. They were very rational furiously defended arguments in their day for some, but not for others, It is the testing of hypotheses that matter in science.
You “postulated” the uniform prior for \beta which is obviously unrealistic.
Next, you cooked up your own criterion for “replication success” that nobody uses and for which you have provided no rationale.
You have now managed to convince yourself that this provides a “reason for the unexplained replication crisis.” News flash: Low replication rates are due to QRPs (p-hacking an such) and low signal-to-noise ratios.
One last time:
You’re predicting the event |b_\text{repl}/\sqrt{v_1+v_2}|>1.96 assuming the uniform prior on \beta.
I’m predicting the different event |b_\text{repl}/\sqrt{v_2}|>1.96 assuming a empirical prior on \beta.
So the numerical agreement is just a meaningless coincidence. Let it go!