Your points are excellent and I fully agree with your criticisms of the Petty/Bone approach to clinical trials. I would just like to see a refactoring of themes, with each theme stated once, and designs of ideal trials as you have begun to do above.
What a hot topic!
Well, I will add a few points and then provide a foreign perspective on American critical care research.
First, the rings metaphor Erin suggested. Drawing rings on heterogeneous disease is precisely what is wrong with sepsis research. The current ring is too large, Erin admitted, and people are working in refined rings.
However, drawing any ring to triage patients in or out of a clinical trial for, say, E. coli UTI will cause researchers to miss all the “ringed-out” patients, leading to a massive bias. One should include all E. coli UTI patients to figure out why some patients fare worse, and only then formulate a testable intervention. Anyone grasps it.
I will rephrase it. Prognosis is not diagnosis. Sepsis-3 is a mistake because it uses a prognostic tool (qSOFA, a threshold ring) to define the presence of a disease. It is absurd from a medical perspective.
Medical researchers have forgotten that Medicine is a subsidiary of biology, and epidemiologists/data scientists happily waved Bradford-Hill off, saying plausibility is a matter for the field experts. Unfortunately, the field experts lost contact with real human biology and are trying to deduce biological associations from their desktop computers.
It leads to my second point, where I may disagree with Lawrence (a rare event). You can not deduce causal associations using causal models. There are two problems.
One is conceptual: it’s the hundred-year-old inductivist mistake addressed and clarified by Popper. This is why I wrote earlier in this thread that medical researchers are not scientists. Testing causality without having a previous biological model is inductivism.
The other is quite obvious. In biology, you will never compute all the variables. The inductivist will keep adding variables because inductivists never refute their conjecture. It is also unfeasible. Please think of the sepsis “dysregulated inflammation” proposition. How many new molecules with inflammatory properties have been discovered in the past five years?
In summary, I am saying that:
- Any threshold definition (ring) is a mistake because it defines case severity, not the biologic nature of the disease.
- Top critical care researchers can’t see it, and NIH grant reviewers also can’t.
- Causal inference statistical exercises are useless and will never find a treatment for any disease.
Finally, my last point is that American influence locked all the world in the same trap. I am a Brazilian intensivist. I have spent the last 30 years in the reading side of American critical care research. I have witnessed the gradual “intellectual colonization” process. Brazilian researchers have recently hypothesized that aspirin reduces mortality in septic shock. This is the typical science-mimic they learned from Americans. The intellectual colonization process is complete, and soon no one in the world will be able to correct such mistakes.
Today, we are training new scientists in the mistakes made by American scientists decades ago. Young scientists look for established authorities as role models. We are not only wasting careers worldwide. We trained a generation that won’t understand why they will never find a breakthrough in critical care. Even worse, they might learn to play the grants game and keep kicking the can down the road.
This is no trivial topic. I apologize in advance if I sounded harsh. It comes from a perception that my field of medicine is forever stalled
2 Likes
Thank you Dr. Harrell for the request for me to continue providing my view of the best approach. I am going to slightly disagree with Rafael’s assessment of what I was saying but I will first apologize to Rafael for America’s intellectual colonization of his country’s critical care scientists. I tried to intervene with one of the leading of Brazilian scientists in 2018 but was outgunned by proselytizing US scientists.
Rafael misunderstood my focus on DAGs. The goal is to map out the potential causal mechanisms prior to RCT to avoid pitfalls like REMAP CAP. I do not disagree with Rafael on this point generally but inductive analysis has come a long way and there is much to learn by this method… if it is not taken too far!
However, to emphasize my general agreement with Rafael, I loved the “Book of Why” but the causal bridge too far becomes briefly visible through the fog of brilliance, when the author tries to show that it is possible to prove that smoking induced tar causes lung cancer using DAGs. (Not withstanding this,much advances have been made in supportive processing since that book)
Relevant the best approach to the study of the hundreds of different advanced infection states, it is best to start from the beginning even with the terminology and with the goals. The first goal is to learn about the relational time dimensioned signals generated by the priors, the infection, the human’s response to the infection and the interventions. We need a deep understanding of what the relational time series patterns of onset, worsening, recovery, and recovery failure are in relation to the priors and infections.
So we do not convene a 1990s style task force to determine the triage threshold set for “sepsis” and then initiate a plurality of RCTs to determine treatment effect of drugs X,Y, Z respectively on triaged participants. Instead we start by learning about the infections we seek to cure.
Instead we accept that we are still close to the beginning. So we start with the extreme basics seeing the human from a secular perspective as a time series matrix of signals and an infection and the response to the infection as a distortion of that matrix. Each infection will induce a signature distortion comprised of a plurality of perturbations of signals; lab, vitals, molecules, etc and then recoveries from those perturbations. Those are the data we have in EMR archives in the hundreds of thousands so we start by learning from them.
So in the instant example, we obtain all the EMR available for a given infection (E Coli UTI) and study the distortions and its relational time series components of its baseline and priors, its onset, worsening, complete recovery, incomplete recovery, and recovery failure in timed relation to the TS of treatments.
An unfortunate but useful set of archived E Coli cases received very late or the wrong antibiotics so these provide an opportunity to see the entire E. coli induced distortion progression to death (onset, worsening, recovery failure) just as it would have occurred 2000 years ago. I emphasize this because we have to build on solid evidence. As Rafael points out we cannot start with a “ring” which might be different 30 years from now. A ring derived from evidence may be necessary at some point but that’s not a place to start.
Only after acquiring a solid understanding of the distortion and its features (eg distortion recovery) induced by E Coli UTI we are ready for RCT and even then there must be a solid pathological/pharmacological basis for the tested treatment rather than a broad theory of potential efficacy. Here we need the best minds working toward the common goal of determining the best means to statistically process these data, with mathematical deference to the priors. That is where the physicians need the most help from the statisticians.
For example one of the problems with critical care research is the use of mortality as the primary endpoint. Yet in this discussion you see that deaths attributable to sepsis in a trial are a complicated matter and relate to the country of the trail. )high income vs low income.)
(https://x.com/pulmcrit/status/1187695603888852993?s=
However if the distortion and its recovery are not understood then this is the only hard endpoint one has other than broad one size all guessed threshold sets like SOFA which is not disease specific.
However if instead the task force of experts, physiologists, and statisticians acquires all available retrospective EMR data from all infection types and learn the relational time patterns of recovery to develop disease (infection and source) specific primary outcomes. The outcomes can then relate to the time to recovery TS pattern or the completeness of the TS recovery pattern.
Here you see a moonshot approach. I have used terms like distortions of the “human time series matrix” (HTM) to emphasize the global approach and the requisite baseline state (defining the priors). More familiar but less inclusively economical terms are applicable such as relational time series patterns of both the baseline state and of a target disease and its recovery.
This infection and source specific approach embraces the biological feature of coevolution of each pathogen with humans. This sets the homogeneous thread. After we learn how different infections generate the same targetable pathways we can lump them for RCT testing treatment of that pathway.
I hope this will engender criticisms, discussion, new ideas, better ideas. Another approach is to start at the bench with time series measurements of molecules to derive phenotypic pathways. This still requires the first step of TS matrix analysis because the trajectory of any “diagnostic” of “target” molecule must be considered as a relational part of the distortion and recovery of the TS matrix itself as all such molecules are.
In the last paragraphs of this paper (which paragraphs relate to Time-series patterns, the “integers of physiology”), I talk about the HTM in my pre-pandemic warning about the need for medical education to move away from thresholds and embrace greater relational pattern complexity (which physicians have proven they are fully capable of learning).
“I may be wrong and you may be right, and by an effort, we may get nearer to the truth.”
Karl Popper.
2 Likes
Antibiotic trials in severe infection (sepsis) are not considered to be PettyBone trials as the treatment is selected to target the organisms likely to be present as defined by prior antibiotic and antifungal testing.
Here is a discussion of the use (misuse?) of causal inference in sepsis research. Pipercillian Taxobactam (Zosyn) has been in wide use for decades.
This case is worth considering because it was an instrumental variable analysis as described by Walker et al which became a high profile study potentially altering the standard of care previously defining by RCT.
Note the use of DAGs here. Note the difficulty applying this type of CI to a PettyBone threshold lumped set of different diseases. If this was one disease the CEA (CI) study might have been valid.
This high profile (pot. treatment altering) study and its critique crosses several intellectual axes; lumping, CI, collider bias, RCT and DAGs so it is very cool as a discussion article relevant the complex considerations in critical care science.
I hope the CI group will join in.
https://academic.oup.com/cid/advance-article-pdf/doi/10.1093/cid/ciaf317/63562091/ciaf317.pdf
To look forward we have to identify the issues to be solved. I am finding AI helpful in learning CSM which exposes the potential research flaws. This image is from Chat gpt discussing the present state of critical care research using CSM.




So here we see clearly the things we must fix going forward. I look forward to corrections as I am new to the formal CSM approach. Contrasting Chat Gpts analysis with that of Grok is interesting
Here is Grok.
Functional Relationships for a Generic Petty/Bone RCT
Variables
- T: Treatment (e.g., corticosteroid, T=1 ; control, T=0 ).
- Y: Outcome (e.g., survival, Y=1 , survival; Y=0 , death).
- D: Disease type (e.g., D_1 : bacterial infection; D_2 : viral infection, like influenza).
- C: Observed confounders (e.g., age, shock status, balanced by randomization).
- U: Unobserved confounders (e.g., unmeasured pathogen-specific traits).
- S: Hospital/site (affects disease prevalence).
- SOFA: Threshold-set criterion (e.g., SOFA score).
- PL: Pathogen load (e.g., bacterial or viral load).
- SN: Safety net (antivirals weak for viral infections; antibiotics strong for bacterial infections).
Functional Relationships and Explanations
- S = f_S(U_S) : Hospital/site is determined by external factors (e.g., location, patient population).
- D = f_D(S, U_D) : Disease type (bacterial or viral) depends on hospital (e.g., regional prevalence) and unobserved factors (e.g., pathogen exposure).
- \text{SOFA} = f_{\text{SOFA}}(D, C, U) : SOFA score is set by disease type (e.g., infection severity), patient characteristics (e.g., age), and unobserved factors (e.g., unmeasured severity).
- PL = f_{PL}(T, D, U) : Pathogen load is influenced by treatment (e.g., corticosteroids increase load via immunosuppression), disease type (e.g., viral vs. bacterial), and unobserved factors (e.g., immune response).
- SN = f_{SN}(D) : Safety net is determined by disease type (weak antivirals for viral infections, strong antibiotics for bacterial infections).
- T = f_T(\epsilon, \text{SOFA}) : Treatment (corticosteroid or control) is randomly assigned based on SOFA score eligibility.
- Y = f_Y(T, D, PL, C, SN, U) : Survival depends on treatment, disease type, pathogen load, patient characteristics, safety net strength, and unobserved factors.
REMAP-CAP as a Petty/Bone RCT
REMAP-CAP’s corticosteroid domain is a Petty/Bone RCT, testing hydrocortisone for severe non-COVID CAP, defined by threshold-set criteria (SOFA score or respiratory insufficiency), without primary pathogen stratification (e.g., bacterial, viral, 8.2% influenza), using SOFA scores to identify eligible patients, as confirmed in the search results.
Study Overview
- Design: RCT enrolling ICU patients with severe non-COVID CAP, testing hydrocortisone (50 mg IV every 6 hours for 7 days) vs. control.
- Primary Outcome: 90-day all-cause mortality ( Y=0 , death; Y=1 , survival).
- Randomization: Patients meeting SOFA-based or respiratory criteria are randomized.
- Key Features:
- Enrollment: 658 patients (536 hydrocortisone, 122 control; 15 missing 90-day status).
- Stopped for futility in December 2023 (<5% probability of >20% mortality reduction).
- 8.2% of patients had influenza.
- Protocol breach: 23% of control patients received corticosteroids (median 4 days).
- Results:
- Mortality: Hydrocortisone: 15% mortality (78/521), P(Y=1 \mid do(T=1)) = 0.85 . Control: 9.8% mortality (12/122), P(Y=1 \mid do(T=0)) = 0.902 .
- Secondary Outcomes: Hydrocortisone reduced shock duration (2 days, IQR 2–5) vs. control (3 days, IQR 2–6.75, p=0.05).
- Subgroup Analysis: Odds ratios (influenza: 1.52–1.62; non-influenza: 1.53–1.63) suggest harm.
- Comparison: Contrasts with CAPE COD’s 5.6% mortality reduction in non-influenza, non-shock CAP.
Functional Relationships for REMAP-CAP
The functional relationships are identical to the generic Petty/Bone RCT, applied to REMAP-CAP’s context.
- S = f_S(U_S) : Hospital/site (350 sites) is determined by external factors (e.g., geographic location).
- D = f_D(S, U_D) : Disease type (bacterial or viral CAP, 8.2% influenza) depends on hospital (e.g., regional influenza prevalence) and unobserved factors (e.g., pathogen exposure).
- \text{SOFA} = f_{\text{SOFA}}(D, C, U) : SOFA score is set by disease type (e.g., influenza severity), patient characteristics (e.g., age), and unobserved factors (e.g., unmeasured organ dysfunction).
- PL = f_{PL}(T, D, U) : Pathogen load is influenced by hydrocortisone (increases viral load via immunosuppression), disease type (e.g., higher viral load in influenza), and unobserved factors (e.g., immune status).
- SN = f_{SN}(D) : Safety net is determined by disease type (weak antivirals for viral CAP, strong antibiotics for bacterial CAP).
- T = f_T(\epsilon, \text{SOFA}) : Hydrocortisone or control assignment is random for patients with qualifying SOFA scores or respiratory insufficiency.
- Y = f_Y(T, D, PL, C, SN, U) : 90-day survival depends on hydrocortisone, disease type, pathogen load, patient characteristics, safety net strength, and unobserved factors.
Probabilities from REMAP-CAP
- Survival Probabilities:
- Hydrocortisone: P(Y=1 \mid do(T=1)) = 0.85 (15% mortality, 78/521).
- Control: P(Y=1 \mid do(T=0)) = 0.902 (9.8% mortality, 12/122).
- Disease Types: 8.2% influenza; no specific P(Y=1 \mid do(T), D_i) or P(D_i) , but odds ratios (influenza: 1.52–1.62; non-influenza: 1.53–1.63) suggest harm.
- Protocol Breach: 23% of control patients received corticosteroids (median 4 days).
Causal Effect (ATE)
\text{ATE} = E[Y \mid do(T=1)] - E[Y \mid do(T=0)]
E[Y \mid do(T=1)] = 0.85
E[Y \mid do(T=0)] = 0.902
\text{ATE} = 0.85 - 0.902 = -0.052
Varying Responses Across Different Diseases
Threshold-set criteria lump diseases, causing varying responses:
- Influenza Subgroup (8.2%): Odds ratios (1.52–1.62) suggest hydrocortisone increases mortality via immunosuppression increasing viral load ( PL ), worsened by weak antiviral safety nets ( SN ).
- Non-Influenza Subgroup: Odds ratios (1.53–1.63) show no benefit, but CAPE COD’s 5.6% mortality reduction suggests benefits with strong antibiotic safety nets ( SN ).
- Heterogeneity Impact: The negative ATE (-0.052) reflects harm in influenza (weak safety net) and neutral effects in bacterial CAP (strong safety net), averaged due to lumping.
- Protocol Breach: 23% control group contamination may reduce harm’s magnitude.
Alignment with REMAP-CAP as a Petty/Bone RCT
- Petty/Bone Characteristics: REMAP-CAP uses SOFA-based criteria, lumping bacterial, viral, and influenza-related CAP (8.2% influenza).
- Results Alignment:
- Futility and Harm: ATE (-0.052) reflects higher mortality (15% vs. 9.8%), consistent with futility and odds ratios suggesting harm via immunosuppression ( PL ) and weak antiviral safety nets.
- Disease Heterogeneity: The functional relationships show lumping obscures benefits (e.g., CAPE COD’s findings with strong antibiotic safety nets).
- Secondary Outcomes: Reduced shock duration (p=0.05) suggests benefits, but survival shows no advantage.
- Critique: REMAP-CAP’s design averages opposing effects, with immunosuppression worsening influenza outcomes (weak antiviral safety net) and antibiotics mitigating bacterial CAP effects, aligning with the Datamethods critique.
Summary
The generic Petty/Bone RCT functional relationships show how threshold-set criteria, immunosuppression increasing pathogen load, and disparate safety nets (weak antivirals, strong antibiotics) obscure treatment effects. REMAP-CAP, as a Petty/Bone RCT, yields a negative ATE (-0.052) due to higher mortality (15% vs. 9.8%), driven by immunosuppression in influenza and varying safety nets, explaining futility and contrasting with CAPE COD’s targeted findings.
Some of the conclusions of Grok seem over stated. Grok seems to draw from CAPE COD (which excluded influenza) in making its analysis of REMAP CAP.
The point of all of this is that if you read REMAP CAP you will not see that the authors have contemplated any of these considerations, even in retrospect. This is why we have to get back to studying the raw data. Everyone is focused the relationship of Y and T but that is not at all what often happens in the ICU. Here are images from actual time series matrices of severe infection.
Below are the main potential progressions to outcomes of severe infection.
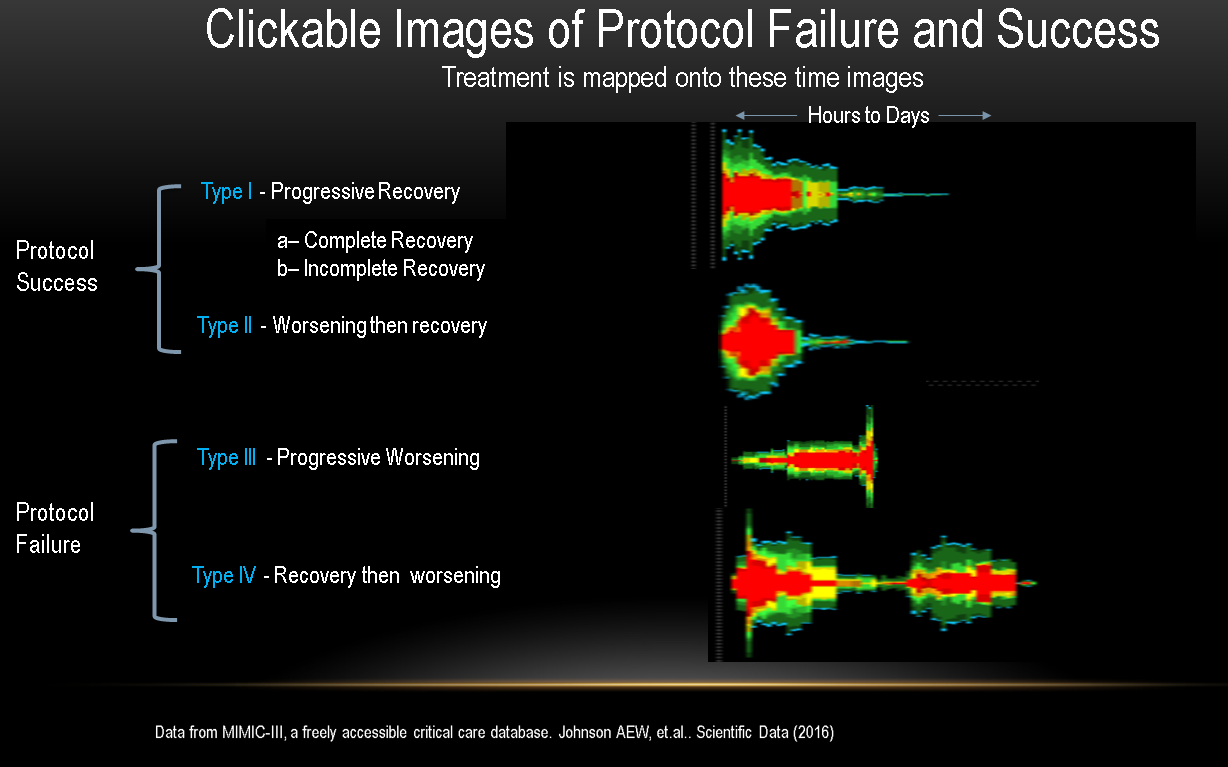
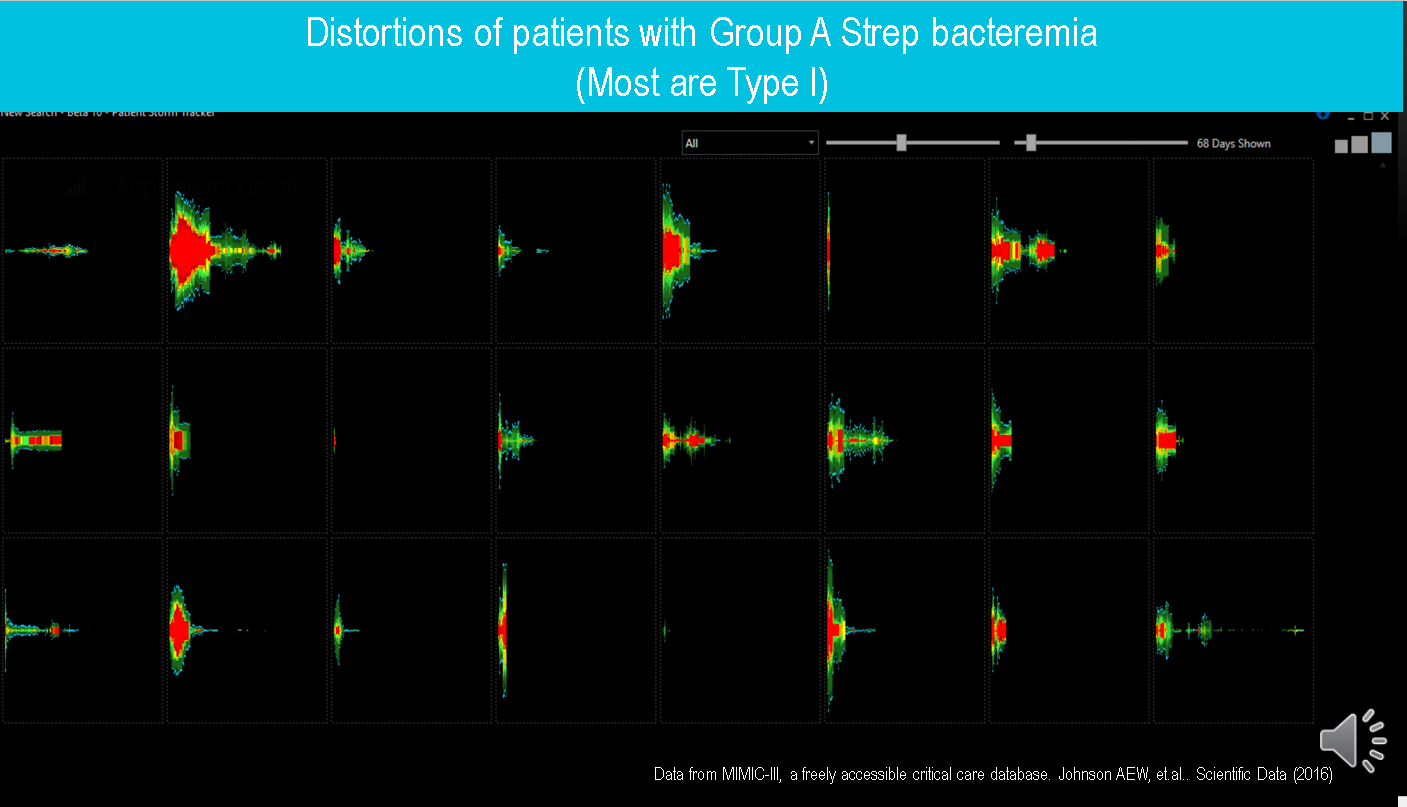
Below you see the outcome where T (antibiotics) consistently produces recovery unless given too late because the organism Group A strep is highly sensitive.
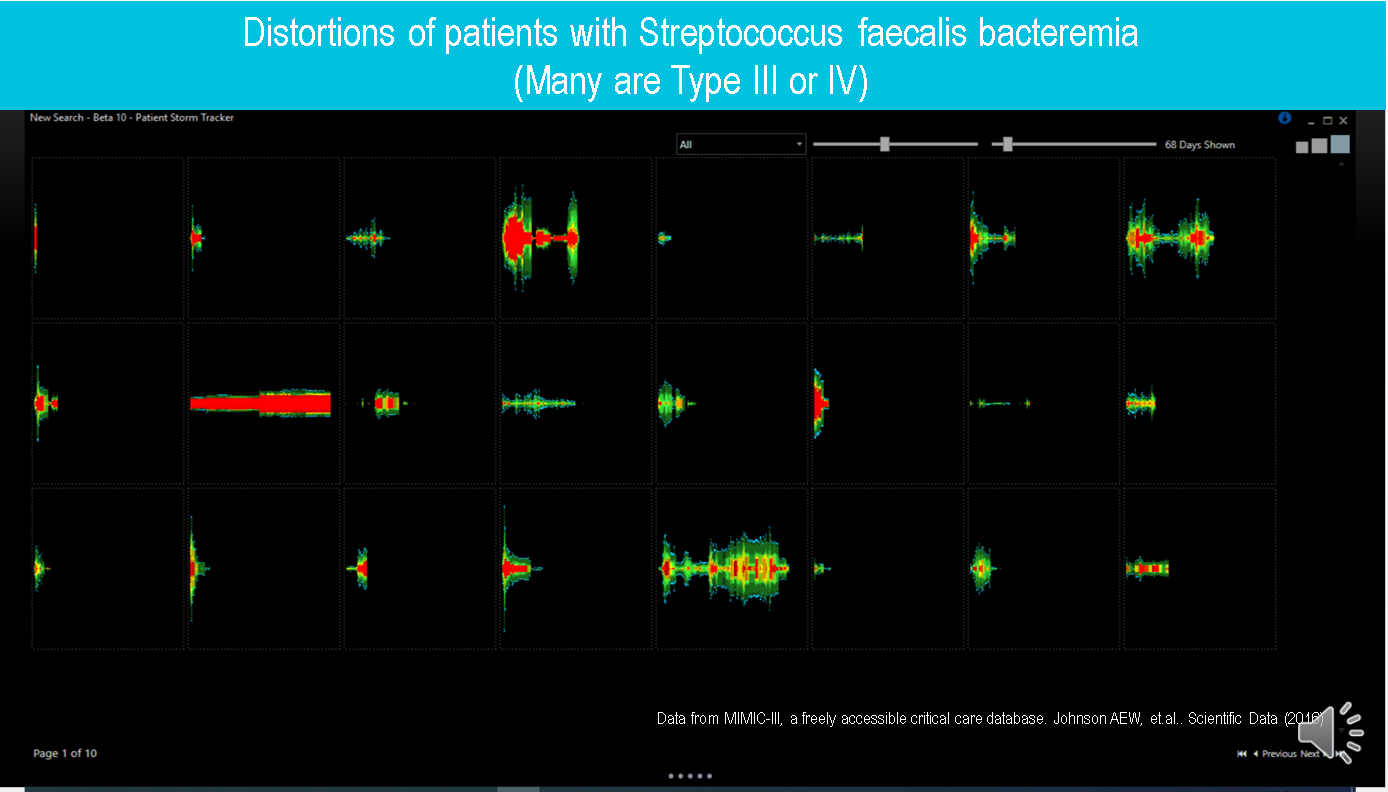
below you see the opposite with a less responsive organism and more case complexity.
Now consider that the treatment T corticosteroids is added to the antibiotics in an RCT. So we have to first understand the heterogeneity not simply state that it is exists as nebulous linguistic artifact of critical care medicine called a “heterogenous syndrome”. Then we can do better experiment design.
1 Like
Very interesting. On a minor formatting note many of the symbols in \LaTeX math mode were not surrounded by dollar signs to make them render in math notation.
1 Like
(…) During decades of negative sepsis and ARDS RCTs, field experts may have failed to inform that T is not only disease-agnostic, but also cause-agnostic. (…)
I’d be delighted to have comments on my attempt to explain the Petty/Bone mistake using DAGs. Here is the main figure.
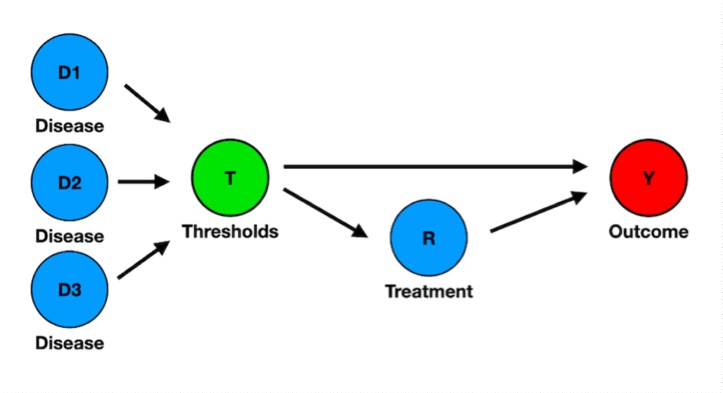
Here’s the text.
4 Likes
There was a podcast from Berry Associates that discusses many of the problems in sepis that @llynn has tried to bring attention to.
2 Likes
Amazing to watch this after over a decade of trying to induce introspection. One feels sorry for them and it’s sad after so much overconfidence in the past to see the characterization of the “hope and pray” RCT, which is actually the PettyBone RCT.
I spent about 8 million dollars of my own personal funds building the EMR software for the platform they are describing here and they had no interest in it in 2019 as they thought the task forces could define the thresholds X for RCT entry criteria.
For me this is both a wonderful and sad day. So much time has been lost but we can see through all the embarrassed laughter in this podcast that they now see the old PettyBone science is pathological.
There was little actual science discussed in that podcast (most was PettyBone pathological science), but I have to honor Dr. Angus for his courage. Almost no one in the main is that intrepid. Hats off.
I want to say a special thanks to Frank. I don’t think this would have happened without this forum. Over 7000 reads in this thread about the PettyBone RCT.
20.5k reads in the 2020 thread describing “What is a fake measurement and how are they used in critical care”.
and 20.1k reads of “The end of the syndrome in critical care”.
My goal in coming to datamethods back in ~2019 was to induce exactly the introspection and real (non synthetic) paradigm shift in critical care science which is evident in this podcast. They are not completely there yet but the dogma dam has broken.
The next step is to end the task force guessing of threshold sets (X) and acknowledge the source and pathological nature of PettyBone science.
We can’t have a two tiered system where the task-force promulgates the PettyBone rules to the masses (including low income countries) while the privileged at major US universities move the next generation critical care research.
Thanks to everyone for the discussion. Science is wonderful. It gives you chills when it self-corrects. It’s not there yet but the intellectual water is flowing through the dam.
1 Like
This discussion has moved over to the review of the two main RCT species types. Join the discussion at the link.
In this article, the second article of the RCT structure analysis series, present the two species of RCT which have evolved and are now in common use. These two species of RCT are profoundly different and should not be conflated. The second species studies “synthetic data generating processes” (SDGPs) or their equivalents at a third layer estimand.
The three articles together describe the present spectrum of divergent RCT structures. Below a link is the second article in the RCT structure trilogy.
The third RCT structural analysis article in this series, linked here, is still a preprint.
This third article above, is the most important for clinicians and statisticians to understand because it discloses the discovery of the three estimand layers of many modern RCTs. One goal of this work is to bring clinicians and statisticians together discussing the origin and structure of the gate and the associated causal coherence of the trial as this has a major impact on the safety of the transportability of the gate triggered treatment into clinical space.
The catastrophe of the transport of ARDS meta analysis to generate “strong” ventilator guidelines of the COVID pandemic has been the catalyst for my efforts here to explain (after the smoke and pain has mitigated) why, mathematically, that happened, but it is up to those with the lectern, who teach medical statistics and trial theory to trialists and clinicians, to assure it does not occur again. Of course I’m always supportive of open debate of these issues. On the other hand anyone who thought this would all go away was wrong. Once you see the third layer estimand and the “cause mixture paradox”, you can’t unsee it.
The important discovery to teach is that one species of trials operates at a third layer estimand where unsafe transport is a real risk and must be addressed by design because the trial is anchored to a synthetic data-generating process (SDGP) rather than a causal biological system.
SDGPs are not what we are treating at the bedside.