Dear Dr. Doi,
Thank you for sharing your work. I appreciate the initiative of replacing ‘statistical significance’ with ‘statistical divergence.’ After a first glance, I present some major criticisms that I hope are constructive.
“Although Fisher’s framework was one of inference, Jerzy Neyman and Egon Pearson tried to move this to a decision framework later on 5 . Regardless of framework, at its core, the p value is a measure of validity of the chosen hypothesis as a source of the study data.”
I believe two key issues must be emphasized. First, the P-value is derived from a model presumed to be perfectly valid before calculation. Thus, the validity of the very P-value as a measure of the relationship between the data and a specific mathematical hypothesis (e.g., the null hypothesis) is conditional on the plausibility of the remaining assumptions that make up the chosen model (e.g., data normality, absence of outliers, linearity, etc). Moreover, there could be numerous different models (and therefore hypotheses) capable of yielding similar P-values (and these P-values cannot ‘tell us’ which of such models is more - or less - valid). Consequently, considering the P-value as a measure of the validity of a mathematical hypothesis as the source of the observed, numerical data is an overestimation of its capabilities. This problem further amplifies when assessing a scientific hypothesis (e.g., absence of a drug effect), since the underlying validity request encompasses scientific and epistemological assumptions (e.g., absence of human bias, appropriate study design, correct setting of measurement instruments).
Secondly, the Neyman-Pearson decision P-value is not designed to provide information about the contextual properties or characteristics of the chosen hypothesis: it is merely an intermediate tool for making a decision based on a rule of behavior - disconnected from the statistical evidence of the individual study - that gains practical significance (i.e., to limit Type I errors to α*100%) only through a high number of valid, equivalent replications. As recently shown by @Sander, it is essential to clearly distinguish between the divergence P-value and the decision P-value, not only for semantic reasons but also for procedural ones (e.g., the inadequacy of the latter in TOST procedures) [1].
In light of this, I propose that the sentence under consideration and all similar expressions or concepts be removed or substantially reformulated.
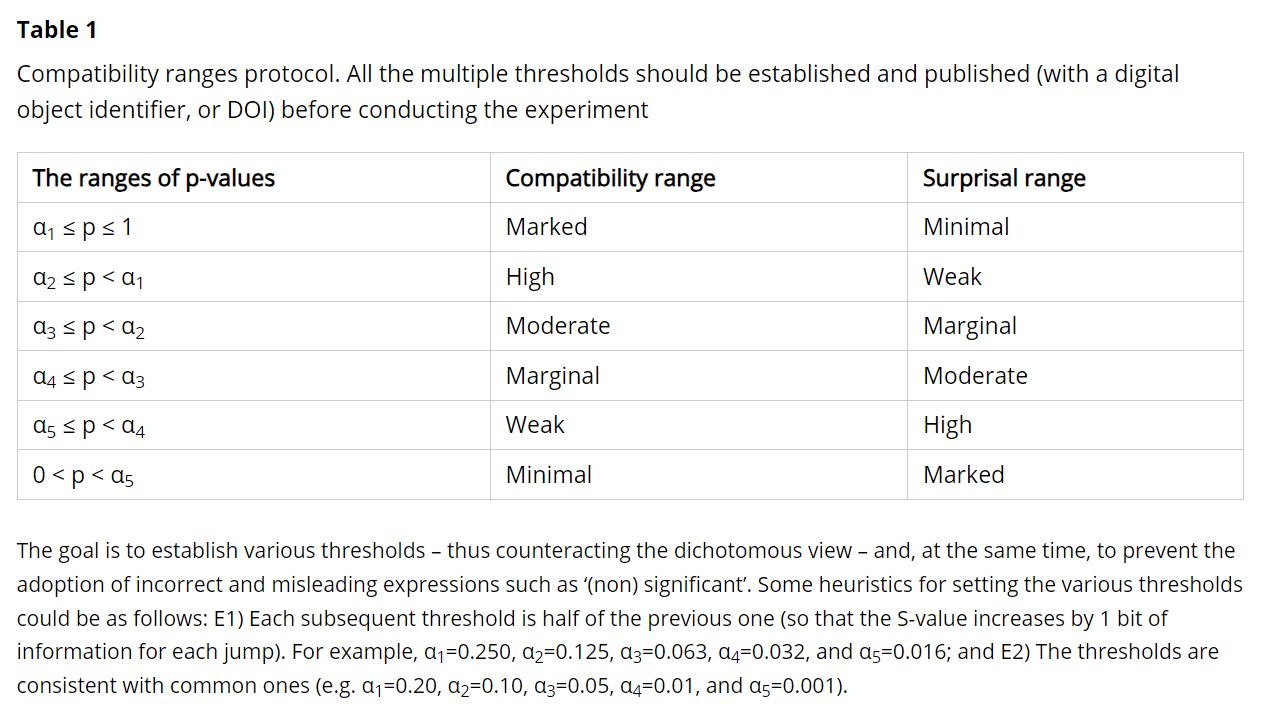
“For clarity we propose the following use of the terms: a) Statistically divergent: When the p-value is less than the divergence level (e.g. two sided p < α). b) Statistically non-divergent: When the p-value is greater than or equal to the divergence level (e.g.,two sided ≥ α). c) Non-divergent interval (nDI): The interval associated with the stated divergence level, usually 95%. d) Continuum of p-values: represents the degree of divergence of the hypothesized model with the data, usually trichotomized44 to no, weak and strong divergence. Divergence can also be used to indicate distance from the divergence threshold e.g. approaching statistical divergence.”
This proposal simply shifts the problem of dichotomization from ‘statistical significance’ to ‘statistical divergence.’ However, this can generate further confusion as the definition of ‘statistical divergence’ - unlike that of ‘statistical significance’ - is linked to an objective, measurable quantity: The mathematical-geometric discrepancy of the experimental test statistic from the model’s prediction. In particular, asserting ‘non-divergence’ means claiming that the test statistic is exactly equal to 0 (in any other case, non-zero divergence exists). At most, one can speak of the ‘relevance’ or ‘strength’ of the divergence, the evaluation of which depends on the scientific context (e.g., prior information on previous evidence and costs, risks, and benefits) [2].
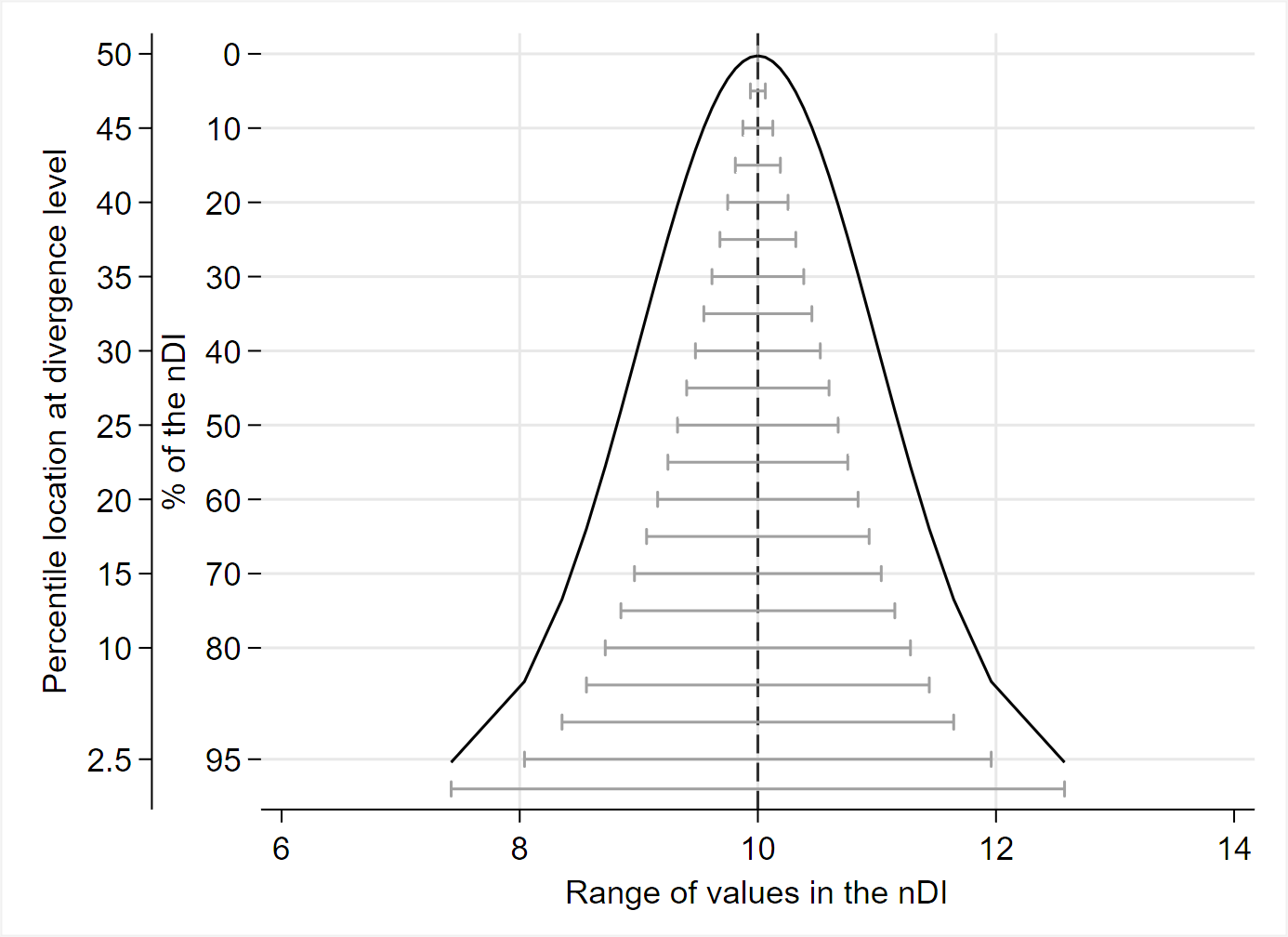
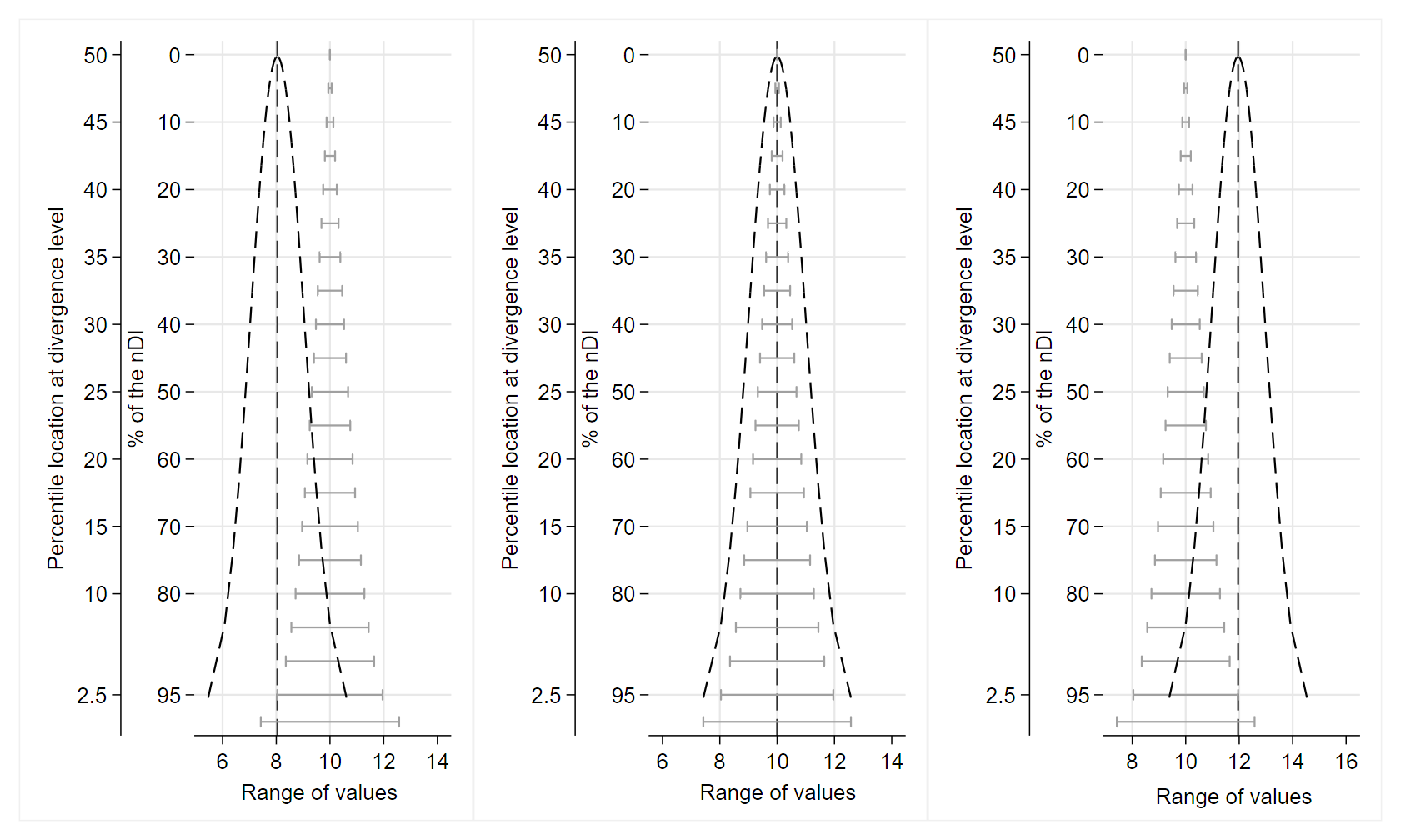
Accordingly, I suggest a modification: from ‘non-divergence interval’ to ‘less-divergence interval.’ For instance, a 95% LDI contains all the mathematical hypotheses related to a real effect or association that are less divergent with the data (P ≥ 0.05) than those outside the interval (P < 0.05), as assessed by the chosen model. In this regard, I also emphasize the importance of adopting methods to address the scaling problem of P-values in quantifying the refutational-information content of the divergence statistic (e.g., Shannon information, i.e., the log-transform of P-values into S-values) [1]. For example, in both statistical and information-theoretic terms, P = 0.005 represents relatively large divergence whereas P = 0.16 does not, but at the other end of the P-value scale, P = 0.84 and P = 0.995 both represent very little divergence even though they are the same ‘distance’ apart on the scale (i.e., 0.995 - 0.84 = 0.16 - 0.005 = 0.155). Upon taking their negative logarithms, as done for example in Shannon-information theory, using base 2 logs of P (S-values) we see that P = 0.005 (S = 7.6) represents 5 more bits of information against the model than does P = 0.16 (S = 2.6), whereas P = 0.84 and P = 0.995 both represent less than half a bit of information against the model [1]. The S-value is thus a measure of the information divergence of the data from the model.
“[…] we could not reconcile a common language across p values and confidence intervals using ‘compatibility’ […]”
Yet this reconciliation is done in some articles cited in your paper and is very simple: A Fisherian (divergence) P-value is an index of compatibility of the data with the tested parameter value, given the model, and a 95% CI is the compatibility interval which shows all parameter values that have P ≥ 0.05 and thus are more compatible with the data than those outside the interval (P < 0.05). That shows how the common language for compatibility that connects interval estimates to P-values. This connection is all the more reason to link your proposal to ‘compatibility’ terminology, because divergence can then be seen as a degree of incompatibility and a degree of nondivergence can be seen as compatibility. I honestly believe that the term ‘compatibility’ fits even better than the term ‘divergence’ since high (resp. low) P-values correspond to high (resp. low) compatibility; On the contrary, high (resp. low) P-values correspond to low (resp. high) divergence. Nonetheless, your proposal has merit as long as the terminological scenario is presented in an impartial, complete manner.
As a final note, I recommend paying closer attention to the history of statistical testing and avoiding overattributions of ‘statistical significance’ to Sir Ronald Fisher (a mistake I have made myself in the past). For example, Karl Pearson mentioned the ‘significant vs. non-significant’ dichotomy as early as 1906 (p.181 and p.183) [3]. Furthermore, the concept of the P-value was already quite common in the French literature by the 1840s - so much so that later in the 19th century there were subsequent complaints about what we now call ‘P-fishing’ (see sec. 2.4 and 3.7 of Shafer) [4].
I really hope this helps.
Best regards,
Alessandro Rovetta
REFERENCES
-
Greenland, S. (2023). Divergence versus decision P-values: A distinction worth making in theory and keeping in practice: Or, how divergence P-values measure evidence even when decision P-values do not. Scand J Statist, 50(1), 54–88. DOI: 10.1111/sjos.12625
-
Amrhein, V., & Greenland, S. (2022). Discuss practical importance of results based on interval estimates and p-value functions, not only on point estimates and null p-values. Journal of Information Technology, 37(3), 316-320. DOI: 10.1177/02683962221105904
-
Pearson, K. (1906). Note on the Significant or Non-Significant Character of a Sub-Sample Drawn from a Sample. Biometrika, 5(1/2), 181–183. DOI: 10.2307/2331656
-
Shafer, G. (2019, September 28). On the Nineteenth-Century Origins of Significance Testing and P-Hacking. DOI: 10.2139/ssrn.3461417