I also ended up responding on PubPeer to the paper put out by Bababekov et al. (comment awaiting moderation), but here it is:
"Despite statisticians warning against the use of observed power for decades (Hoenig & Heisey, 2001), the practice continues, usually from research groups who are unaware of the problems with it. Bababekov et al. (the authors of this paper) have not only defended their use of observed power in previous papers, even when criticized by statisticians who have looked into the problem, but unfortunately, they encourage others in surgical science to do the same.
The arguments put forth in this paper have no mathematical or empirical basis. Meaning, Bababekov et al. have not given any mathematical proofs or simulated data to make their case. Their argument merely consists of,
“Although it has been argued that P value and post hoc power based on observed effect size are mathematically redundant; we assert that being redundant is not the same as being incorrect.”
“We believe this redundancy is necessary in the unique case of surgical science, as post hoc power improves the communication of results by supplementing information provided by the P value.(12) Moreover, post hoc power provides a single metric to help readers better appreciate the limitation of a study.”
The problem is that this practice is not only redundant, it is incorrect and highly misleading. This can easily be shown with simulated data (see attached image). Here, I simulate 45,000 studies from a normal distribution and where I have set a true between-group difference of d = 0.5.
Group A has a mean of 25 and standard deviation of 10, and group B has a mean of 20 and also a standard deviation of 10. Thus, (25-20)/10 gives us a standardized effect size of 0.5. This is the true effect size, something we would rarely know in the real world (the true effect size is unknown, we can only attempt to estimate it).
In this simulation, the studies can be categorized by nine different sample sizes, meaning they have varying true power (something we know because it’s a simulation). True power ranges all the way from 10% to 90% and each of the nine scenarios has samples simulated from a normal distribution.
.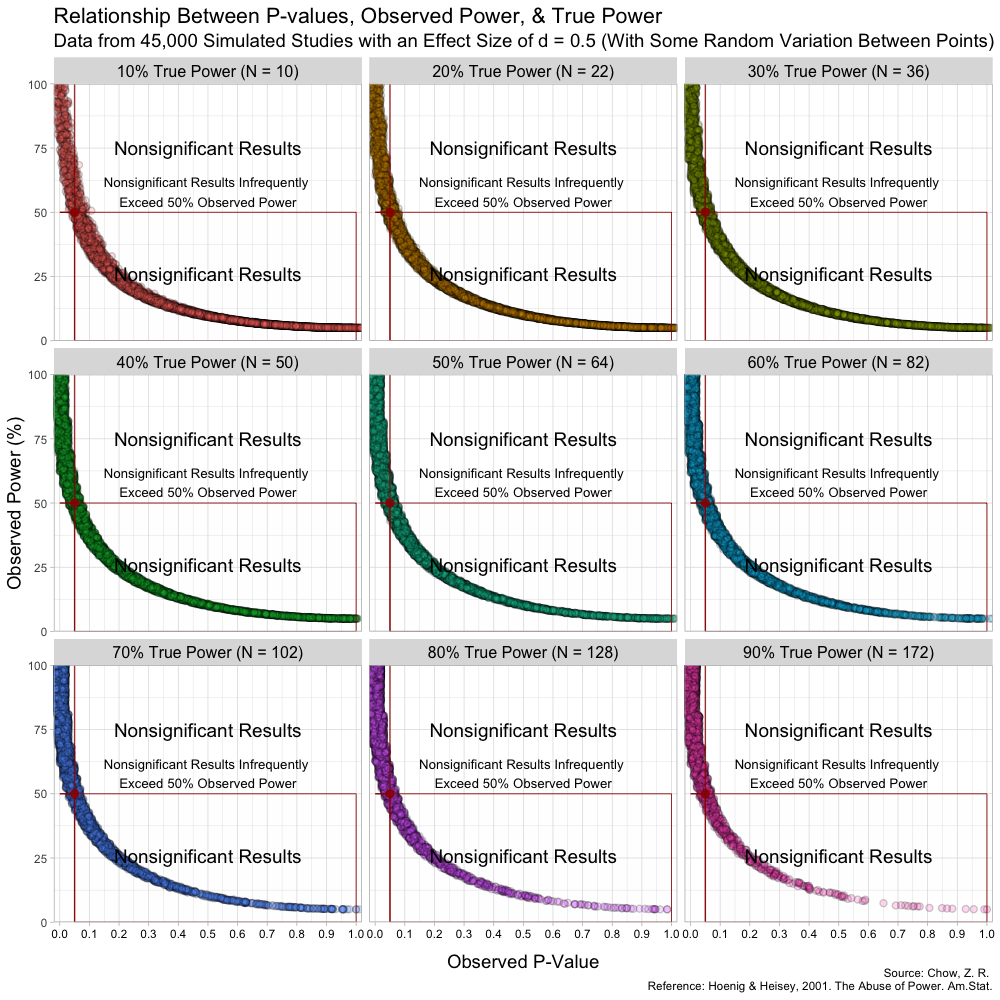
The graph above has some random variation added between points to make them out, but in reality, this (below) is what the graph looks like without any random variation at all. (These are not lines, but actual points plotted!)
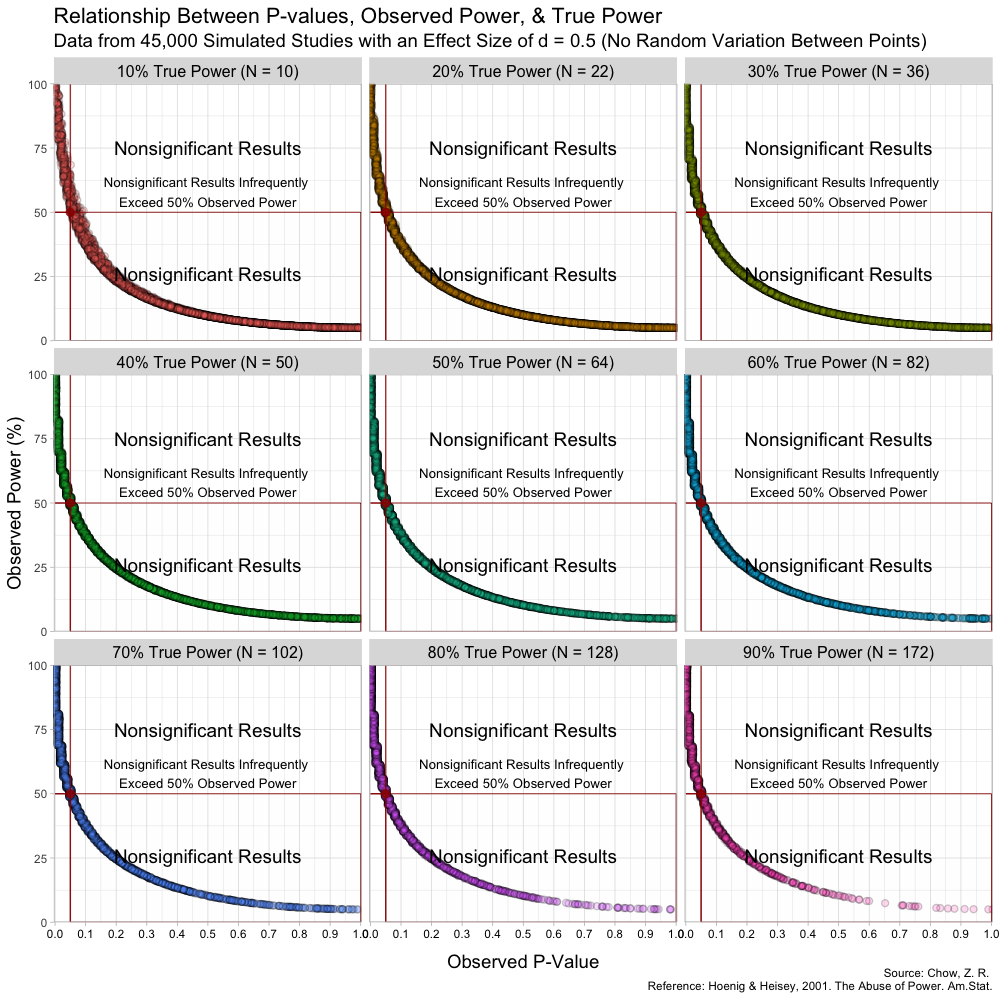
The transitions can also be seen here:

Notice that despite true power being known for each of these studies, observed power highly varies within these scenarios, especially for studies with low(er) power. For example, when true power is set at 10%, many studies yield results showing “observed power” of 50%. Therefore, if we were to follow the recommendations put forth by Bababekov et al. in several scenarios, we would mistakenly put more confidence in results that truly have low power and which yield noisy estimates. Meaning it is not reliable in “improving the communication of results”.
This is because Babakev et al. does not seem to understand long-term frequencies. Statistical power is a frequentist concept, meaning that if someone designs a study with the hope of the test correctly detecting a dimensional violation by the test hypothesis (such as the null hypothesis) 80% of the time, this will occur in the long term if there is a violation of assumptions and given other assumptions.
This does not mean that the study itself has an 80% probability of correctly detecting a violation. For example, when we say that a fair coin has a 50% probability of getting either heads or tails, it does not mean we expect the coin to always give us results that fairly balance the distribution of heads and tails. We will not always expect alternating results of heads and tails (H T H T H T). In fact, it is very plausible that if we flip the coin 10 times, we may get all heads or all tails. However, in the long term, we expect the proportion of heads and tails to be fairly equal.
Furthermore, because the P-value is a random variable and measures random error in the estimate (Greenland, 2019), taking it (observed P) from a single study and transforming it into a distorted version of power (observed power) is beyond fallacious. The authors not only confuse observed power and true power, but they also confuse the random variable P with its realization, observed P. Observed P-values are useful because they indicate statistical compatibility between the observed data and the test hypothesis.
If they are being used for decision rules with a set alpha, and the researchers suspect that a type-II error was very likely, they can use the computed confidence/compatibility/consonance intervals to see what effect sizes are within the interval and how wide the interval estimates are (which measure random error/precision).
However, Bababekov et al. does not see this as a solution as they argue here,
“An alternative solution to mitigate risk of misinterpreting P > 0.05 is for surgical investigators to report the confidence intervals in their results along with the P value.”
“However, the general audience would likely pay more attention to the overlap of confidence intervals in a comparative study with two or more comparison groups with multiple confidence intervals, and still misinterpret the findings as demonstrating equivalency.”
The problem here is that investigators confusing overlapping intervals for equivalency is a cognitive problem (Greenland, 2017) where they do not understand what frequentist intervals are rather than a defect in the method itself.
A computed frequentist interval, such as a 95% confidence/consonance interval contains all effect sizes that yield P-values greater than 0.05 (Cox, 2006). Of course, the computed point estimate, often the maximum likelihood estimate (MLE), has the largest P-value, and values close to it, which will have slightly smaller P-values than the MLE, indicate greater statistical compatibility than effect sizes that are further from the MLE, which will have much smaller P-values.
Thus, it is largely irrelevant whether two or more confidence/consonance intervals overlap. The useful questions are:
- how wide are these intervals?
- how much do they overlap?
- what effect sizes do they span?
Better than computing a single interval estimate for a particular alpha level is to compute the function, where every interval estimate is plotted with its corresponding alpha (10%, 15%, 25%, 50%, 90%, 95%, 99% confidence/consonance intervals), since the the 95% interval is largely arbitrary and a relic of NHST with a 5% alpha.
Bababekov et al. instead sees observed power as being a solution to the “problems” they highlight with interval estimates,
“Power provides a single metric to help readers better appreciate the limitation of a study. As such, we believe reporting power is the most reasonable solution to avoid misinterpreting P > 0.05.”
This argument further highlights the problems with trying to come to conclusions from single studies. The authors wish to answer
“Was my study large enough and reliable, and if not, what single metric can I use to better understand how reliable the decision (reject/fail to reject) is?”
For this, they have found a method, one that they reify, that helps to address their uncertainties of the data-generation process, but unfortunately, it is unreliable and cannot do what they wish it does.
As others have pointed out above, the arguments put forth in this paper are fallacious and thus the manuscript itself is defective and has the potential to seriously mislead many surgical investigators who are not well versed in statistical methods. Letters to the editor (of which there are numerous) and corrections are simply not enough. A retraction is necessary when a manuscript is this defective."
edits: some formatting and added link to the original publication
second update: included two visualizations, one with random variation between points to make out the points and not confuse them for lines, and one without any jitter
third update: added a gif to show transitions